
The C++ standard library contains many classes and functions that integrate easily into a project, are safe, and have been tested on many cases. However, you pay for the convenience and the all-you-can-eat nature with performance. In games, if performance isn't put first right away, then by the end of the project you accumulate so much technical debt that it's often easier to throw everything out and start over. Straightforward use of the standard library, in most cases where you need performant and efficient code — and I don't only mean games right now — turns out not to be the best choice.
The examples below conclude a series of articles in which I tried to collect interesting moments of using various data structures used in game development, their extensions and opportunities for improvement.
The article is aimed at readers who aren't C++ gurus or connoisseurs of the language's subtleties, but are generally familiar with the language and its ideas; knowledge of x86 assembly isn't required, I'll be attaching links to quickbench code examples to explain why I give one piece of advice or another.
Sometimes I'll be telling horror stories here, but most of these cases got in the way of software working normally in prod, so I had to treat them with respect.
Thank you, Habr user, for walking this path with me through a series of articles about C++ gamedev — from light acrobatics with strings and containers, to tricky allocators and multithreading. You not only supported my interest in collecting scattered pieces into something whole and self-contained, but also helped turn technical notes into a living dialogue about game development. I hope these articles became not just a good weekend read, but also a reason for your own experiments, refactoring and new ideas. The game isn't over yet!
Game++. Bonus. Performance traps <=== You are here
Most slow code appears either out of laziness or out of too much cleverness, and usually it's genuinely clever and fashionable code. But instead of opening the profiler, we just pile on more fashionable code. And powerful hardware relaxes you a lot, and there you go — std::map starts getting used where there should be a simple array. Or we stuff std::function, shared_ptr, variant everywhere, allocate at runtime, copy by value in a lambda, hoping the compiler will "optimize something there" — well, it'll optimize something, of course, but it won't think for us. And then QA complains that the game on the Xbox Series X lags like a calculator. Who knew that the atomic increments of shared_ptr aren't free? Everyone. Everyone knew. In modern software probably everything can be slow, starting from allocations and ending with reading from disk; below there will be a not-very-long list, but for some reason out of all the projects only these cases stuck vividly in my memory, although there were many more, you can't remember them all. And you, dear Habr user, surely have a couple of stories that could add to this list — don't be shy to tell them in the comments. Let's go!
Memory allocation is evil, and there's not enough evil to go around
The first thing you learn when developing games for consoles is minimal allocations per frame, which fundamentally contradicts the committee's guidelines on using standard-library containers (https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Rsl-arrays)
SL.con.1: Prefer using STL array or vector instead of a C array
Reason C arrays are less safe, and have no advantages over array and vector. For a fixed-length array, use std::array, which does not degenerate to a pointer when passed to a function and does know its size. Also, like a built-in array, a stack-allocated std::array keeps its elements on the stack. For a variable-length array, use std::vector, which additionally can change its size and handles memory allocation.
A common piece of advice is to prefer std::vector over plain C arrays and static vectors, because it's safer and preserves ownership control of the resource. This is quite reasonable, especially if we assume the vector will grow during operation. However, if there's no need for growth and performance is critical, there are ways to achieve better results.
Usually a vector stores pointers internally, one or more; some pointers (like the end element and the capacity) can be replaced with numbers, but that doesn't change the essence — it's still the same contiguous chunk of memory:
begin— a pointer to the start of the data,end— a pointer to the position right after the last element (used to compute the current size),capacity_end— a pointer to the end of the allocated memory block (defines the maximum size without reallocation).
struct vector {
T* begin;
T* end;
T* capacity;
};This triple of pointers lets std::vector quickly check the size, whether there's room for new elements, iterate, shift, delete, and so on. But you pay for it with indirect access to the elements: the data is stored not inside the object, but at the address that begin points to. This breaks data locality in the cache; the first several accesses to a vector's data (usually 10–15), until the CPU's internal structures adapt to the new pattern, go "cold", they're several times slower than subsequent accesses, so working with small vectors is even more costly than with large ones — there are always cache misses there and the algorithm doesn't have time to "spin up". This effect is known as "cold start" — it's a slightly more general concept, but the essence is the same: small data structures are always more expensive to process.
The "cold-start" effect
When you first access the elements of a vector, the data isn't yet loaded into the CPU cache, so a lot of cache misses happen. After several accesses the data gets loaded into the cache (L1, L2, L3), and subsequent accesses become significantly faster — "cache warm-up".
Especially noticeable with:
The first pass over a large vector
Accessing data after it's been evicted from the cache (cold start)
Working with vectors whose size exceeds the cache size (cache poisoning)
To minimize this effect, techniques are used such as:
Prefetching (preloading data)
Cache-friendly algorithms with good spatial locality
"Warming up" the cache before the main computations
Even if the vector is small, its data is always on the heap, which is significantly more costly in terms of time. The way a vector is initialized matters. For a concrete example, suppose we have a number N, and we want to return a vector containing the squares of the first N numbers:
[0, 1, 4, 9, 16, ...]
A modern vector implementation is wrapped in a large number of checks — for the current size, for going out of bounds of the array, for the need to reallocate memory. The compiler will generate a bunch of extra code (in particular, calls to operator new, memmove and operator delete) and exception handling, so the generated code turns out badly bloated for no reason at all. Even for a simple function that returns some array of elements of a known size — all these checks will be included. (https://godbolt.org/z/vK5W93z8W). This is how ordinary developers write when they want to return some array of values; here a memory reservation in the vector is even done, otherwise it'd be downright sad.
std::vector<int> createVector(int size) {
std::vector<int> result;
result.reserve(size);
for (int ii = 0; ii < size; ++ii) {
result.push_back(ii * ii);
}
return result;
}Asm (vector<int>)
makeVector(int):
push rbp
push r15
push r14
push r13
push r12
push rbx
sub rsp, 24
xorps xmm0, xmm0
movups xmmword ptr [rdi], xmm0
mov qword ptr [rdi + 16], 0
test esi, esi
js .LBB0_1
mov rbp, rdi
je .LBB0_27
mov r12d, esi
movsxd rbx, esi
lea rdi, [4*rbx]
call operator new(unsigned long)
mov r15, rax
mov qword ptr [rbp], rax
mov qword ptr [rbp + 8], rax
lea r9, [rax + 4*rbx]
mov qword ptr [rbp + 16], r9
xor r14d, r14d
mov r8, rax
mov rbx, rax
mov qword ptr [rsp + 16], rbp
mov dword ptr [rsp + 12], r12d
jmp .LBB0_6
.LBB0_7:
mov dword ptr [rbx], r13d
add rbx, 4
mov qword ptr [rbp + 8], rbx
add r14d, 1
cmp r12d, r14d
je .LBB0_27
.LBB0_6:
mov r13d, r14d
imul r13d, r14d
cmp rbx, r9
jne .LBB0_7
mov rdx, rbx
sub rdx, r8
movabs rax, 9223372036854775804
cmp rdx, rax
je .LBB0_9
mov rax, rdx
sar rax, 2
mov ecx, 1
test rdx, rdx
je .LBB0_13
mov rcx, rax
.LBB0_13:
lea rdx, [rcx + rax]
movabs rsi, 2305843009213693951
mov r12, rsi
cmp rdx, rsi
ja .LBB0_15
mov r12, rdx
.LBB0_15:
add rcx, rax
movabs rax, 2305843009213693951
cmovb r12, rax
test r12, r12
mov qword ptr [rsp], r8
je .LBB0_16
mov rbp, r15
mov r15, r9
lea rdi, [4*r12]
call operator new(unsigned long)
mov rbp, rax
mov r8, qword ptr [rsp]
mov r9, r15
jmp .LBB0_19
.LBB0_16:
xor ebp, ebp
.LBB0_19:
mov rdx, r9
sub rdx, r8
mov rax, rdx
sar rax, 2
lea r15, [4*rax]
add r15, rbp
mov dword ptr [rbp + 4*rax], r13d
test rdx, rdx
jle .LBB0_21
mov rdi, rbp
mov rsi, r8
mov r13, r9
call memmove
mov r9, r13
mov r8, qword ptr [rsp]
.LBB0_21:
add r15, 4
sub rbx, r9
test rbx, rbx
jle .LBB0_23
mov rdi, r15
mov rsi, r9
mov rdx, rbx
call memmove
mov r8, qword ptr [rsp]
.LBB0_23:
test r8, r8
je .LBB0_25
mov rdi, r8
call operator delete(void*)
.LBB0_25:
add rbx, r15
mov r15, rbp
mov rbp, qword ptr [rsp + 16]
mov qword ptr [rbp], r15
mov qword ptr [rbp + 8], rbx
lea r9, [r15 + 4*r12]
mov qword ptr [rbp + 16], r9
mov r8, r15
mov r12d, dword ptr [rsp + 12]
add r14d, 1
cmp r12d, r14d
jne .LBB0_6
.LBB0_27:
mov rax, rbp
add rsp, 24
pop rbx
pop r12
pop r13
pop r14
pop r15
pop rbp
ret
.LBB0_9:
mov edi, offset .L.str.1
call std::__throw_length_error(char const*)
.LBB0_1:
mov edi, offset .L.str
call std::__throw_length_error(char const*)
jmp .LBB0_29
mov rdi, rax
call _Unwind_Resume
mov r15, rbp
.LBB0_29:
mov rbx, rax
test r15, r15
je .LBB0_31
mov rdi, r15
call operator delete(void*)
.LBB0_31:
mov rdi, rbx
call _Unwind_Resume
But if you simply return some filled array of elements, such a lightweight array, the compiler will produce completely different code, free of these wrappings. Half of the results returned as vectors in an application don't change, and if they don't change — why use an expensive vector for that?
std::unique_ptr<int[]> createSharedArray(int size) {
int *result;
result = new int[size];
for (int ii = 0; ii < size; ++ii) {
result[ii] = (ii * ii);
}
return std::unique_ptr<int[]>{result};
}Asm (std::unique_ptr<int[]>)
makeArray(int):
push rbp
push r14
push rbx
mov ebp, esi
movsxd rbx, esi
mov ecx, 4
mov rax, rbx
mul rcx
mov r14, rdi
mov rdi, -1
cmovno rdi, rax
call operator new[](unsigned long)
test ebx, ebx
jle .LBB1_11
mov ecx, ebp
cmp ebp, 7
ja .LBB1_3
xor edx, edx
jmp .LBB1_10
.LBB1_3:
mov edx, ecx
and edx, -8
lea rsi, [rdx - 8]
mov rbp, rsi
shr rbp, 3
add rbp, 1
test rsi, rsi
je .LBB1_4
mov rdi, rbp
and rdi, -2
neg rdi
movdqa xmm0, xmmword ptr [rip + .LCPI1_0]
xor esi, esi
movdqa xmm1, xmmword ptr [rip + .LCPI1_1]
movdqa xmm2, xmmword ptr [rip + .LCPI1_2]
movdqa xmm3, xmmword ptr [rip + .LCPI1_3]
movdqa xmm4, xmmword ptr [rip + .LCPI1_4]
.LBB1_6:
movdqa xmm5, xmm0
paddd xmm5, xmm1
movdqa xmm6, xmm0
pmuludq xmm6, xmm0
pshufd xmm6, xmm6, 232
pshufd xmm7, xmm0, 245
pmuludq xmm7, xmm7
pshufd xmm7, xmm7, 232
punpckldq xmm6, xmm7
pshufd xmm7, xmm5, 245
pmuludq xmm5, xmm5
pshufd xmm5, xmm5, 232
pmuludq xmm7, xmm7
pshufd xmm7, xmm7, 232
punpckldq xmm5, xmm7
movdqu xmmword ptr [rax + 4*rsi], xmm6
movdqu xmmword ptr [rax + 4*rsi + 16], xmm5
movdqa xmm5, xmm0
paddd xmm5, xmm2
movdqa xmm6, xmm0
paddd xmm6, xmm3
pshufd xmm7, xmm5, 245
pmuludq xmm5, xmm5
pshufd xmm5, xmm5, 232
pmuludq xmm7, xmm7
pshufd xmm7, xmm7, 232
punpckldq xmm5, xmm7
pshufd xmm7, xmm6, 245
pmuludq xmm6, xmm6
pshufd xmm6, xmm6, 232
pmuludq xmm7, xmm7
pshufd xmm7, xmm7, 232
punpckldq xmm6, xmm7
movdqu xmmword ptr [rax + 4*rsi + 32], xmm5
movdqu xmmword ptr [rax + 4*rsi + 48], xmm6
add rsi, 16
paddd xmm0, xmm4
add rdi, 2
jne .LBB1_6
test bpl, 1
je .LBB1_9
.LBB1_8:
movdqa xmm1, xmmword ptr [rip + .LCPI1_1]
paddd xmm1, xmm0
pshufd xmm2, xmm0, 245
pmuludq xmm0, xmm0
pshufd xmm0, xmm0, 232
pmuludq xmm2, xmm2
pshufd xmm2, xmm2, 232
punpckldq xmm0, xmm2
pshufd xmm2, xmm1, 245
pmuludq xmm1, xmm1
pshufd xmm1, xmm1, 232
pmuludq xmm2, xmm2
pshufd xmm2, xmm2, 232
punpckldq xmm1, xmm2
movdqu xmmword ptr [rax + 4*rsi], xmm0
movdqu xmmword ptr [rax + 4*rsi + 16], xmm1
.LBB1_9:
cmp rdx, rcx
je .LBB1_11
.LBB1_10:
mov esi, edx
imul esi, edx
mov dword ptr [rax + 4*rdx], esi
add rdx, 1
cmp rcx, rdx
jne .LBB1_10
.LBB1_11:
mov qword ptr [r14], rax
mov rax, r14
pop rbx
pop r14
pop rbp
ret
.LBB1_4:
movdqa xmm0, xmmword ptr [rip + .LCPI1_0]
xor esi, esi
test bpl, 1
jne .LBB1_8
jmp .LBB1_9std::unique_ptr
Compiler developers know about this too, and if you use a vector template constructed "to size", then the call will be very similar to the last result, which works without most of the checks. This code will work fast, almost like a raw allocation, if RVO kicks in — the key word here is if. RVO does help in real programs, but it's a fragile mechanism, more on that in the next paragraph.
std::vector<int> createPrealloc(int size) {
std::vector<int> result(size);
for (int ii = 0; ii < size; ++ii) {
result[ii] = ii * ii;
}
return result;
}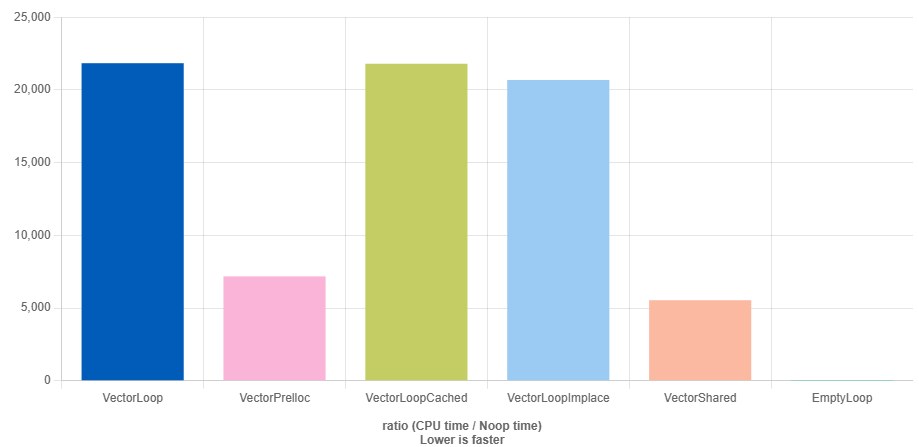
https://quick-bench.com/q/ETpIgVgy1uwpYkJhn5tQRdegCm4
War story
Back in 2019 I was invited (through a mutual acquaintance) to audit the codebase of one St. Petersburg studio's engine; they were already thinking about moving to Unreal but didn't want to abandon their own either. I won't name it, but you've definitely played one of their hidden-object games. The old team that actually wrote the engine had ridden off into the sunset, and the new team just piled on new functionality under the guidance of an ?ffective manager, without much understanding of how the engine was built under the hood. They didn't think about performance either, not at all, and all over the engine there was work with raw std::string, returning megabyte-sized vectors and creating std::map inside loops. To say the engine was in a bad way is putting it mildly. On the average Android of the time the game pushed 30 fps on an empty scene with a couple dozen objects, but since the scenes were mostly static, nobody really noticed the freezes and fps drops. My buddy and I sat over the profiler for a week and rolled out a report saying it'd be cheaper to bury the stewardess and move to Unreal. That's how improper memory handling buried a rather decent in-house engine.
Treacherous RVO
The simplest way to start managing memory is to allocate it dynamically every time you need it. This approach is considered ideal, encouraged in many programming books and even by the committee. A gray-haired computer-science professor who hasn't debugged a real application in ages lectures students on how you should build classes through strings, vectors and maps — this isn't my invention, I just went to a couple of lectures by an existing "maître" when I had to fix an fps drop caused by new colleagues.
And it really is very easy to use. Need a new instance of an animation when the player lands on a ledge? Allocate memory. Need to play a new sound when a goal is reached? Just allocate more memory.
Chaotic dynamic memory allocation in theory helps keep memory usage to a minimum, because you allocate only what's really needed and no more. But in practice everything turns out much worse, since each allocation suddenly turns out to have an unexpectedly large overhead, which starts to accumulate if the programmers get too relaxed. This is a great way to shoot off both of the compiler's legs, so it does less optimizing of our code.
struct ParticleSystem {
std::vector<float> particles; // vector here on purpose,
// it was Particle, float is just for the test
ParticleSystem(size_t count) : particles(count, 1.f) {}
};
std::optional<ParticleSystem> make_editable_particle_system() {
ParticleSystem ps(100); // heavy allocation
return ps;
}
std::optional<ParticleSystem> make_baked_particle_system() {
const ParticleSystem ps(100); // `const` blocks RVO
return ps;
}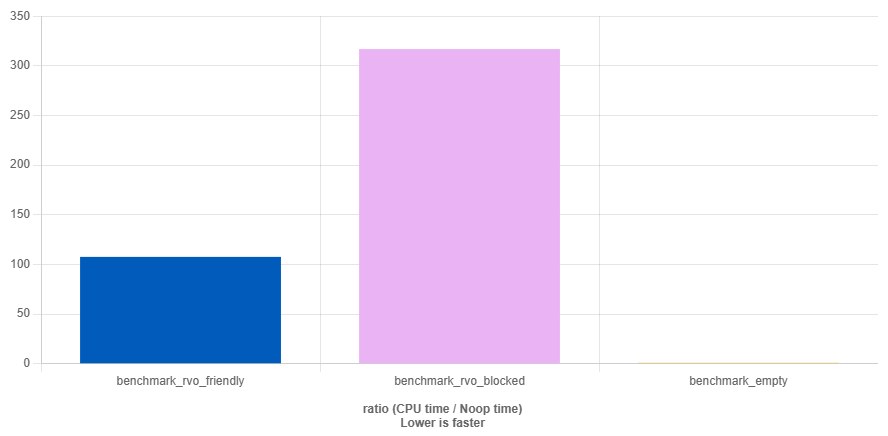
https://quick-bench.com/q/2ysRdpKJWSklB1mDA1b0EuFysuE
War story
Once upon a time a particle system lived in a game, didn't bother anyone, didn't get in anyone's way. The time came to refactor it and make it more configurable in the effects editor — fire, smoke, sparks, residual trails... We gave designers the ability to tune about a hundred particle parameters, with different dynamics and lifetimes. Everything looked great in the editor — the effect was assembled from a multitude of parameters, and you could change colors, speed, particle types on the fly. The system returned this effect as a ParticleSystem object, which was then passed on into the game.
Designers got bolder and started rolling out more complex effects, but here's the trouble — scenes started freezing on them. We dug into the code, and there was this nonsense with const, which disabled RVO. That is, instead of a single object creation there was creation + a copy. And since the object was large (one of the effects exceeded 10k elements), it really lagged, and at 60 fps there was a clear freeze, and not one of the compilers of the day managed to do a move. Why they made it const and missed this in review is a separate topic.
The heavy callback
Memory allocations are of course harmful, but at least you can detect them with a profiler and remove them, whereas with newfangled things like chains of calls and callbacks everything is much more complicated. Suppose we have a set of units and we want to iterate over them and do some work, for example run different logic for friends and for enemies. The old logic is written through a loop with conditions, and some payload:
struct GameObject {
uint32_t id;
float lifetime;
int visible;
GameObject() : id(0), lifetime(0.0f), visible(std::rand()) {}
};
bool isVisibleForEnemy(const GameObject &o) noexcept {
return o.visible && !(o.visible & (o.visible - 1));
}
bool isVisibleForFriends(const GameObject& o) noexcept {
constexpr std::uint64_t visibleForFriends = 0x8000;
return o.visible > 0 && (visibleForFriends & o.visible == visibleForFriends);
}
template <typename callback_type_>
void executeRealEntityWork(const GameObject& o, callback_type_ &&callback) noexcept {
if (o.visible) {
callback(o);
}
for (std::uint64_t condition = 1; condition <= o.lifetime; condition++) {
callback(o);
}
}
static void FilterEntitiesLambda(benchmark::State &state) {
float sum = 0, count = 0;
for (auto _ : state) {
sum = 0, count = 0;
for (const auto &o : entities) {
if (!isVisibleForEnemy(o) && !isVisibleForFriends(o))
executeRealEntityWork(o, [&](const GameObject &o) {
sum += o.lifetime;
count++;
benchmark::DoNotOptimize(sum);
});
}
}
}
In a fit of refactoring we decided to rewrite this through std::function, so everything would be by the guidelines, fashionable and pretty. And we get an increase in function runtime and compile time by several times when using std::function as callbacks. Although it simplifies the interface, it also leads to (!possible) heap allocations and drags the "noisy" <functional> — one of the largest headers of the standard library — into the compilation unit.

The same code, side view, but slower
template<class T>
void forEachEntities(T& ent, std::function<void(const GameObject& o)> const &callback) {
for (const auto &o : ent) callback(o);
}
void filterEntitiesStl( //
const GameObject &o,
std::function<bool(const GameObject &o)> const &predicate,
std::function<void(const GameObject &o)> const &callback) {
if (!predicate(o)) callback(o);
}
void executeRealEntityWorkStl(
const GameObject &o,
std::function<void(const GameObject &o)> const &callback) {
executeRealEntityWork(o, callback);
}
static void FilterEntitiesStdFunction(benchmark::State &state) {
float sum = 0, count = 0;
for (auto _ : state) {
sum = 0, count = 0;
forEachEntities(entities, [&](const GameObject &o) {
filterEntitiesStl(o, isVisibleForEnemy, [&](const GameObject &o) {
filterEntitiesStl(o, isVisibleForFriends, [&](const GameObject &o) {
executeRealEntityWorkStl(o, [&](const GameObject &o) {
sum += o.lifetime;
count++;
benchmark::DoNotOptimize(sum);
});
});
});
});
}
}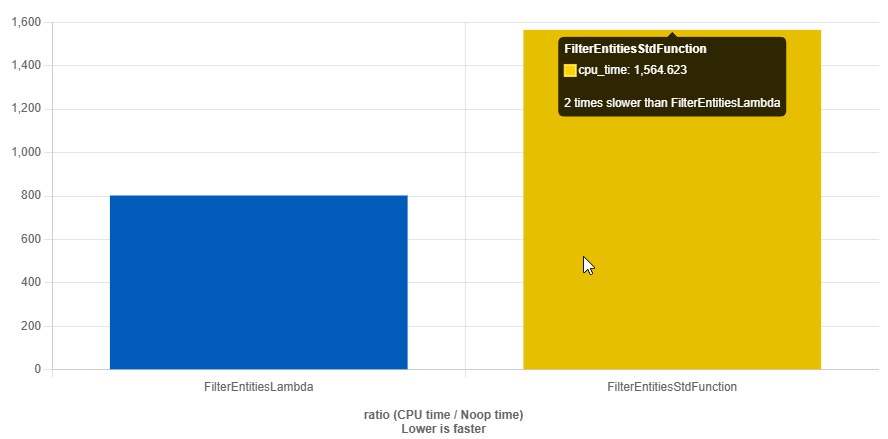
https://quick-bench.com/q/8WeASFxS-1cNykvdtZR2Hu14mlM
War story
We were once reworking a game AI — nothing special really: behavior tree nodes, a couple dozen conditions and actions, all in place. And then someone clever in quotes (unfortunately, me) suggested: instead of homemade callbacks and template functions, let's build it through std::function. You know, readability, extensibility, "C++ Core Guidelines" and all that. We built it — beautiful! The code is neat, the interfaces tidy, you can pass anonymous lambdas everywhere, from scripts or from code, you can change part of the behavior on the fly. Everything flexible, everything by the guideline. A holiday for a designer, really.
It got much worse when we shipped this to "prod". First the build time grew, not much — about 10% — but we'd moved only 2 NPCs out of a hundred onto the new system. We started looking at CI, found hundreds of <functional> inclusions, 27Kloc, which our careless fix had sneaked into very many places, and then it got worse: periodic in-frame freezes began. And not from rendering, not from loading, but right in the AI logic. What the h...
We started looking — and std::function, it turns out, sometimes allocates on the heap. Especially when it's not just a lambda but a lambda with captured state. And our functions get called several hundred times per frame, and the trend was growing, because new NPCs were being connected. There's your "possible allocations". On the PlayStation these allocations started hitting the allocator so hard that the FPS dropped by half. In the end… it was already too late to throw it all out and bring back the old version; more than a year had been spent on the new AI, so we had to spend a long time hugging the profiler fixing this little thing and writing workarounds.
Sometimes "fashionable" and "beautiful" is a luxury that not everyone can afford at runtime.
Expensive identifiers
Many libraries, including the STL (std::string), Folly::fbstring or boost::string, use a technique called "small string optimization" (SSO, Small String Optimization). This is a trick where short strings are stored right inside the string object, without allocating memory on the heap. Thanks to this, performance improves and memory fragmentation is reduced, especially with frequent operations on short strings (for example, identifiers, names, keys). The SSO implementation depends on the compiler and the standard library. In libstdc++ (GCC 13), std::string usually stores strings up to 15 bytes right in the object (sizeof(std::string) = 32 bytes). In libc++ (Clang 17), the limit is 22 bytes with sizeof(std::string) = 24 bytes. Custom string implementations also usually support up to 32 bytes of local storage, and that's usually enough for most identifiers — until a component system comes into the engine, and long composite strings. And then the string length starts directly affecting the game's performance, and it makes sense to switch to other identifier systems not tied to strings.
https://quick-bench.com/q/J5ZTH1z_E7dE3OSU4ih3S2lB4II
War story
In Sims Mobile, all the in-game logic — from character actions to object behavior and triggers in the house — was built on callbacks and interaction through string identifiers. The original Sims had the same system but on numeric IDs; porting it to Unity didn't work out for various reasons, so a custom one on raw strings was written.
Partly this was done temporarily, for debugging convenience. Each object had dozens of parameters: "fridge_open", "bed_sleep_short", "career_event_barista_1", "interaction_social_highfive" and so on. Designers could throw together reactions just by composing different strings and hanging a handler on them, for example fridge_open_sim_pants if a sim opened the fridge in his proverbial underpants.
In the early builds all this information was stored and passed by copying, to be able to do traces and logs of the work. This simplified debugging, made the tools convenient for designers, but time passed, and the temporary system became the main one, and everyone forgot why it was even made, but in prod too many problems started to surface.
The biggest pain was load time — an ordinary level took 3–4 minutes, and obviously players won't just stare at the screen for that time, even the most devoted sim-lovers. A sims' house with dozens of objects and several active sims, each with its own states and action queues, caused an avalanche of string comparisons. The player sees "a sim got out of bed and went to wash up", while under the hood the code does hundreds of string matchings: which animation? which interaction type? which outfit? All of these are long, composite names, often 130+ characters.
As content filled in, microfreezes appeared even from trivial actions: a sim tries to choose an available toilet — and spends 2–3 ms on it, just iterating over string keys in the routing logic. Seems like nonsense, but when you have 4 sims and 500 active objects on screen, and all of them are actively doing something, the game started to stutter, especially on weak devices.
We had to rework it: instead of strings — integer IDs. Each string involved in the logic was assigned a stable uint32_t at build time, and at runtime only number comparison happened. This removed most of the problems: scenes started loading faster, sims made decisions instantly, and the background simulation (even when the user is in the menu) stopped draining the phone's battery. We made everything nice and convenient for the designers and they barely cried, but that's a separate story.
Moral — no one ever again suggested "let's just pass a string in the parameters".
The raging sine
Standard-library functions such as sin, cos, tan and others are implemented with an emphasis on the maximum possible precision. For this, complex algorithms are used, which significantly slows down execution, so many developers prefer to write their own trigonometry with lower precision.
Absolute precision isn't always critical. It's acceptable to use approximate methods to significantly speed up computations — for example, when precision down to the fourth decimal place is already excessive. One such approximation is expanding the sine function into a Taylor–Maclaurin series and representing the function as a polynomial around some point. If we limit ourselves to the first few terms of the expansion, then the expression for sin(x) will look like this:
sin(x) ≈ x - (x³)/6 + (x⁵)/120Such approximate sines are used in simulating breathing, the swaying of leaves, floating objects, oscillations on water or simulating wind in puddles. Besides, you can make the sine even simpler on weak devices.
An attempt to do it "right" and by the formula will most likely fail and be more expensive than the original, because the CPU can compute sine in hardware:
std::pow(phase, 3) / 6 + std::pow(phase, 5) / 120Such an approach sharply reduces the number of floating-point operations, especially if you get rid of the std::pow calls and replace them with manually expanded multiplication. Precision is lost in the process, especially at large argument values, but for small values of x the result comes out close enough to the real one and is computed many times faster. Nobody said the leaves have to describe perfect circles.
double x2 = phase * phase;
double x3 = x2 * phase;
double x5 = x3 * x2;
offset = phase - x3 / 6.0 + x5 / 120.0;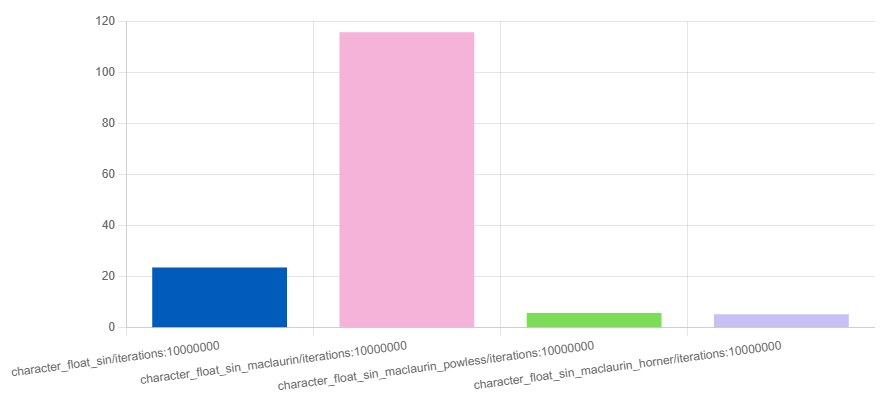
https://quick-bench.com/q/HTCdf5dII1Be1vvb02rv_DGrhjw
War story
In Sims Mobile the usual character animations weren't used — there were too many actions with objects that had to be animated, but the sims had to animate quickly and smoothly while walking around the house, picking up a mug, opening the fridge and other actions. Instead, an animation system based on curves built between locators (points on an object) was written. That is, you could set a point on the mug and a point on the hand, and the sim would smoothly move its hand to the mug, and then just as smoothly to its mouth.
Inside the animation, each of the sims' limbs — legs, arms, head — worked as a physical bone driven by the given curves. These curves were built from sine functions to make the actions look realistic. Every simulation tick the code made hundreds of std::sin calls, per sim, per animated bone. Even on modern ARM chips this was a problem — to say nothing of mid-tier Androids.
As a temporary solution we replaced std::sin with an approximation using a Maclaurin series. Visually the animations stayed the same — smooth and lively, well, at least the producers didn't notice. But the fps grew — by 8–10 FPS in a scene.
A couple of months later a proper implementation with table interpolation and SIMD instructions was brought into the project, but it was exactly that "dirty" Maclaurin series that saved more than one gray hair on the lead programmer's head.
Slow division
Floating-point computations are more resource-intensive, but integer operations can unexpectedly turn out significantly worse in performance. This especially concerns the division (/) and modulo (%) operations, which are considered among the slowest arithmetic operations in the processor. Dividing 32-bit integers usually takes about 10 CPU cycles — that's roughly 2.5 nanoseconds.
If the divisor is known at compile time, the compiler can perform an optimization called strength reduction (https://en.wikipedia.org/wiki/Strength_reduction)
In this case, division is replaced with faster multiply and shift instructions, even for numbers as large as the maximum 32-bit one. This replacement makes division cheaper. For the compiler to treat a value as known at compile time, it's enough to just use const or constexpr for the optimization. But modern compilers can infer immutability themselves when analyzing a variable's lifetime (clang especially likes to do this, which can cause other bugs, but that's a separate story).
There's another interesting trick: dividing integers through floating-point numbers. Since the 64-bit double type can exactly represent any 32-bit signed integer, you can safely convert int to double, perform floating-point division and cast the result back to int. This lets you use the processor's blocks designed for double operations, which perform real-number division a full five times faster than the integer ALU.
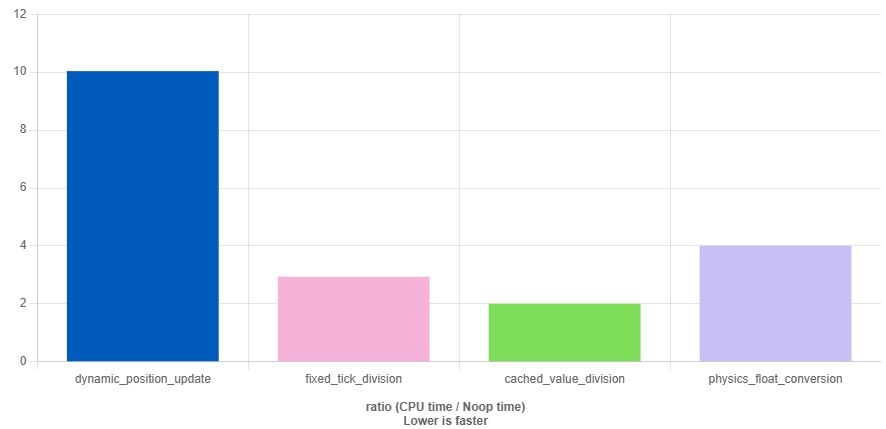
https://quick-bench.com/q/HhAWEpdX5L96VlVcqTb7pz18C6A
War story
There won't be a war story — modern CPUs have enough power for us to think less about such tiny things. But sometimes you still have to — during the port of a game (XBlades 2) to the Nintendo Switch we ran into an unexpected problem: this platform had a frankly weak integer-division block in the ALU, and with a large number of integer-division operations per frame we observed an fps drop (it dropped by 1–2 frames, roughly). Analysis of profiler snapshots showed that a lot of time goes precisely into integer-division operations, which worked fine without issues on PC and the big consoles, and which were actively used in the calculation logic of everything in the game, from game mechanics to shader data. Add to that a relatively slow ~1 GHz CPU and you get an unpleasant bonus in the form of an overall slowdown. We didn't fix it everywhere, because it was a million places and many hours of work; we changed the code only in the truly hot functions.
The cost of cache misses
Once I had to work with an engine like this.
class GameObject {
Transform* transform;
AIBeh* ai;
PhBody* physics;
Animation* animations;
// ... many more components ...
};And this approach was in every class, right down to object positions Point(x, y, z) and the variables x, y, z themselves. Why was it done this way? Well, that's the architect coming/going (a pun). If you thought about separate memory pools for components that would return pointers to pre-allocated memory — think again.
The code was simply written the way it was — each object created everything it needed dynamically; what it didn't need, it didn't create; that's how it was written from the start, apparently the team believed in the "zero cost everything" promise from the committee. Don't believe it — you pay for everything, even for empty pointers.
What was happening with the cache is a separate song. I don't remember the exact numbers anymore, but it was something like this:
L1 cache misses: 70+%
L2 cache misses: 60+%
L3 cache misses: 40+%That is, half the time the processor just waited for data, or tried to fetch it from RAM. What happens with such data organization can be seen in this benchmark.
Benchmark of the disgrace
enum class AccessPattern { Linear, Random };
struct Position {
float x, y, z;
};
struct Health {
int value;
};
struct Team {
int id;
};
template <AccessPattern pattern>
static void GameObjectAccessCost(benchmark::State &state) {
const size_t objectCount = static_cast<size_t>(state.range(0));
struct GameObject {
Position* pos = new Position();
Health *health = new Health();
Team* team = new Team();
};
std::vector<GameObject> gameObjects(objectCount);
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<int> healthDist(50, 200);
std::uniform_real_distribution<float> posDist(-1000.0f, 1000.0f);
for (auto &obj : gameObjects) {
obj.pos->x = posDist(gen);
obj.pos->y = posDist(gen);
obj.pos->z = posDist(gen);
obj.health->value = healthDist(gen);
obj.team->id = healthDist(gen) % 4;
}
std::vector<size_t> accessOrder(objectCount);
if constexpr (pattern == AccessPattern::Random) {
std::iota(accessOrder.begin(), accessOrder.end(), 0);
std::shuffle(accessOrder.begin(), accessOrder.end(), gen);
} else {
std::iota(accessOrder.begin(), accessOrder.end(), 0);
}
for (auto _ : state) {
int totalHealth = 0;
float totalDistance = 0.0f;
for (size_t idx : accessOrder) {
const auto &obj = gameObjects[idx];
benchmark::DoNotOptimize(totalHealth += obj.health->value);
benchmark::DoNotOptimize(
totalDistance +=
std::sqrt(obj.pos->x * obj.pos->x +
obj.pos->y * obj.pos->y +
obj.pos->z * obj.pos->z));
}
benchmark::ClobberMemory();
}
}
BENCHMARK(GameObjectAccessCost<AccessPattern::Linear>)
->MinTime(1)
->RangeMultiplier(8)
->Range(8 * 1024, 128 * 1024 * 1024)
->Unit(benchmark::kMillisecond)
->Name("GameObjectAccess/Linear");
BENCHMARK(GameObjectAccessCost<AccessPattern::Random>)
->MinTime(1)
->RangeMultiplier(8)
->Range(8 * 1024, 128 * 1024 * 1024)
->Unit(benchmark::kMillisecond)
->Name("GameObjectAccess/Random");
Even with sequential access, all of it bottlenecked on memory work, or it just sat there in unloaded scenes, unable to squeeze out even 30 fps.
Linear/8192/min_time:1.000 0.015 ms 0.015 ms 99556
Linear/32768/min_time:1.000 0.065 ms 0.065 ms 21854
Linear/262144/min_time:1.000 0.761 ms 0.762 ms 1906
Linear/2097152/min_time:1.000 9.66 ms 9.59 ms 145
Linear/16777216/min_time:1.000 77.1 ms 77.3 ms 18
Linear/134217728/min_time:1.000 608 ms 602 ms 2
Random/8192/min_time:1.000 0.018 ms 0.018 ms 74667
Random/32768/min_time:1.000 0.144 ms 0.144 ms 9956
Random/262144/min_time:1.000 2.75 ms 2.76 ms 498
Random/2097152/min_time:1.000 66.5 ms 66.2 ms 21
Random/16777216/min_time:1.000 666 ms 664 ms 2
Random/134217728/min_time:1.000 7715 ms 7688 ms 1If you make a simple layout instead of one through pointers, it already gets better. Just from the correct data layout, we have better data locality and higher speed.
struct GameObject {
float x, y, z;
int health;
int team;
};Linear/8192/min_time:1.000 0.014 ms 0.014 ms 99556
Linear/32768/min_time:1.000 0.055 ms 0.055 ms 24889
Linear/262144/min_time:1.000 0.446 ms 0.444 ms 3200
Linear/2097152/min_time:1.000 4.21 ms 4.21 ms 345
Linear/16777216/min_time:1.000 34.5 ms 34.3 ms 41
Linear/134217728/min_time:1.000 268 ms 269 ms 5
Random/8192/min_time:1.000 0.014 ms 0.014 ms 99556
Random/32768/min_time:1.000 0.055 ms 0.055 ms 25600
Random/262144/min_time:1.000 0.705 ms 0.703 ms 1867
Random/2097152/min_time:1.000 19.8 ms 19.7 ms 69
Random/16777216/min_time:1.000 221 ms 221 ms 6
Random/134217728/min_time:1.000 1910 ms 1922 ms 1War story
To my timid remarks, while I was still a mid, that not all was well in the state of Denmark, they simply piled on more tasks. The engine team was confident in its own infallibility and the correctness of the chosen path. For some reason I didn't pass the probation period and went off to work at EA. A year later, in 2015, that studio shut down — not necessarily because of the engine, but it does make you think.
Moral — value the cache, or the cache won't value you.
Hands off std::pair where you need to squeeze out more speed
In reality, any program needs memory — your Captain Obvious. But the operating speed is also affected by how this memory is organized, what structures are used, how they're placed in memory — especially in systems with limited resources.
Arbitrary data types (ADT, Algebraic Data Types) are one of the most desirable and powerful constructs in modern programming languages. They let you create complex types by combining simpler ones — for example, through "or" combinations (sum types, variants) and (product types, structures).
In plain C the only way to model an ADT is manual combination of struct and union, often with an explicit tag to indicate the active field. This is complicated, error-prone and requires careful application. In C++ we can use std::pair, std::tuple — for composite structures, std::variant — for variant values, std::optional — for representing a value that may be absent.
Despite the apparent simplicity and convenience, using these types is not "free" in terms of performance and compile time. This especially concerns std::function — it can lead to hidden heap allocations, as I showed above; <functional>, <tuple>, <variant> are among the "heaviest" headers of the standard library, containing tens of thousands of lines of template code; this code can't be cached and will be recompiled in every compilation unit — yes, only the needed parts, but the file will still be parsed anew.
It's naive to assume that std::pair works just as fast as a simple struct { T1 first; T2 second; }. It all depends on the nuances — how the compiler optimizes templates, whether debug flags are enabled, which standard-library implementation is used (libstdc++, libc++, MSVC STL), how exactly objects are created and copied.
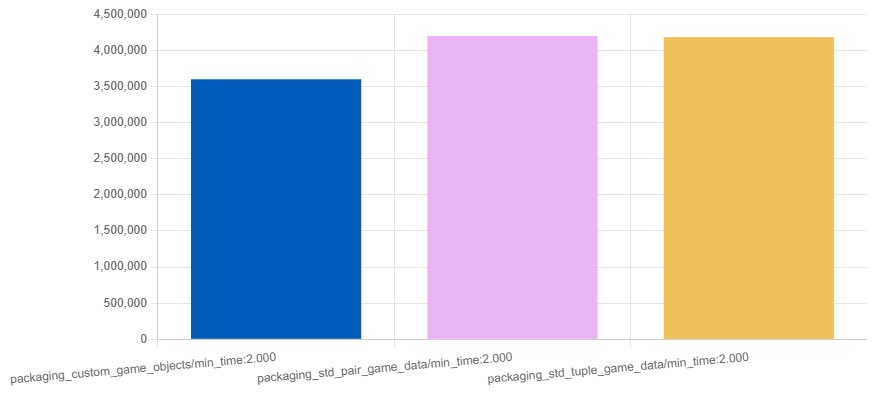
https://quick-bench.com/q/46NOXqH9MFwr0FB0NcoORdClHH8
If you have hundreds of objects, you shouldn't think about things like std::pair — you won't see the difference, except in the profiler. If you have hundreds of thousands of objects that the engine operates on (models, textures, identifiers) — this already spills into seconds, minutes and hours of real time. And even 10% affects the build system.
War story
The St. Petersburg EA office also made SimCity BuildIt, one of the first city-builders for mobile; the engine itself and the resource-packing system were written in C++ — Marmalade (engine) + Marble (build system): textures, animations, level data — everything went through a complex pipeline that had a step for combining the meta-information about each resource into a DB.
The build was written by contractors (not the core team) with active use of modern things — std::pair, std::tuple and std::function for genericity. Each resource-bundle build (especially for iOS) took about 140 minutes, of which around 60+ went into the "metapackers" stage — processes that look simple but are loaded with template structures, like parsing textures, getting sizes, picking parameters for the atlas, adding to the resource system, and so on.
The time grew along with the addition of new objects, and when it crossed two hours someone on the team (not the author of this article, my paws hadn't grown enough back then) went to look at why exactly the metapackers were lagging. They ran the profiler on the build farm and saw a very interesting picture: a sea of time spent generating and copying objects of types std::tuple<std::string, std::function<bool(const ResourceInfo&)>> and std::pair<std::string, std::uint32_t>. All these constructs were passed by value between functions and copied many times — just some kind of factory for copying everything that could possibly be copied.
After getting rid of all this "noisy code", the metapacking step started working several times faster, the bundle build time returned to 60 minutes, and the build itself started torturing RAM less, which was especially rough for Jenkins nodes with a bunch of parallel builds. At the retro they got chewed out for poking into a system that wasn't theirs and now having to support it, and were given a T-shirt with the studio logo for reducing build times. But they could safely have been gifted a new Skoda Yeti — that's roughly how much the company was burning every month on renting capacity for Jenkins. Such fixes rarely make it into presentations or guides — more often into epic fails and retro post-mortems.
Moral — the build farm will endure anything; for optimizing build time you can get a T-shirt and a chewing-out.
The price of virtuality
To use virtual functions effectively, especially in the context of game performance, you need to understand in advance where and how they'll be applied. This may seem like a hard task for developers accustomed to the flexibility of OOP, but with a clear game-object design and a systematic approach (this is rare, but it happens) you can determine where polymorphism is really justified.
There's one important design philosophy you need to accept so that virtual functions don't become a bottleneck: all behavior in the game must be bounded and predictable. This shouldn't be perceived as a restriction of development freedom — these are the natural constraints of frame time. It means that any systems using virtual calls must avoid uncontrolled virtualization of functions at the drop of a hat.
Benchmark code
struct NonVirtual {
int DoWork(int x) const {
return x * 2;
}
};
struct VirtualBase {
virtual int DoWork(int x) const = 0;
virtual ~VirtualBase() = default;
};
struct VirtualDerived : VirtualBase {
int DoWork(int x) const override {
return x * 2;
}
};
static void BM_NonVirtualCall(benchmark::State &state) {
NonVirtual obj;
int sum = 0;
for (auto _ : state) {
sum += obj.DoWork(42);
}
benchmark::DoNotOptimize(sum);
}
BENCHMARK(BM_NonVirtualCall);
static void BM_VirtualCall(benchmark::State &state) {
std::unique_ptr<VirtualBase> obj = std::make_unique<VirtualDerived>();
int sum = 0;
for (auto _ : state) {
sum += obj->DoWork(42);
}
benchmark::DoNotOptimize(sum);
}
BENCHMARK(BM_VirtualCall);
static void BM_FunctionCall(benchmark::State &state) {
std::function<int(int)> func = [] (int x) { return x * 2; };
int sum = 0;
for (auto _ : state) {
sum += func(42);
}
benchmark::DoNotOptimize(sum);
}
BENCHMARK(BM_FunctionCall);------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------
BM_NonVirtualCall 0.327 ns 0.297 ns 1000000000
BM_VirtualCall 1.75 ns 1.72 ns 373333333
BM_FunctionCall 1.46 ns 1.46 ns 448000000War story
This story isn't quite about gamedev, not quite about virtual calls, but very close. In the late 2000s I happened to take part in developing a video-surveillance system that grabbed points from certain parts of a frame and tried to build a 3D model of a face passing through a certain area. The algorithm was pulled from OpenCV, and the main structure in it was Matrix4x4, the classic 4x4 matrix of float. It was used in transformations, computations, and in general the whole face description was a set of 4k of these matrices. The recognition ran on some servers, there were plenty of turnstiles, plenty of passing faces, so this structure was used millions of times per second, but everything worked acceptably, recognizing roughly 0.5 faces per second from a single camera, gobbling up a ton of watts.
Time passed, and management came up with the task of reducing the size of the stored points (read: matrices), wrote a spec, threw it to the team, but instead of using profiling tools or template wrappers, the OOP-on-the-brain programmers simply made a base class IMatrix with a virtual function GetDiff(), from which they inherited Matrix4x4. That is, this function itself didn't participate in the computations.
At first glance the idea looked harmless: a virtual call that returned the diff of changes from the base matrix, which was usually 1–2% and made it possible not to store all 4k points. You can probably already imagine what happened when all this was rolled out to prod? The performance of the computational pipeline dropped sharply.
Now they brought in the profiler and proper developers to fix the bug. Adding the virtual function led to the appearance of a vtable and an increase in the size of Matrix4x4 from 64 to 72 bytes. This broke the alignment and destroyed cache locality, the neat offsets in the arrays floated. The matrices no longer lay densely, and the SIMD logic started working worse. The number of cache misses rose sharply, which led to functions that worked with matrices starting to spend more time. The servers on the IA-64 architecture suffered especially badly, where offsets and logic were specially calculated for maximum cache load and register math, and any deviation in alignment was very critical.
In the end, one day everyone got a beating, and that same night the update was rolled back: the virtual functions were removed, Matrix4x4 became a POD type without a vtable again, and the structure size returned to 64 bytes. All the logic was rewritten through a separate wrapper that did all this itself and in a separate thread. Performance returned to its previous level. Why it wasn't done that way from the start is already a separate story.
Moral — never add virtual functions to base math structures, especially those that participate in tight loops, SIMD computations or are stored in raw arrays. Even a single virtual can mess things up badly and seriously slow down the computations.
And on that note, really, game over!
UPD: special thanks to @Serpentine, who edited and fixed errors in the articles.
← All articles