

In game development, dynamic and static arrays are the main tool for working with a set of objects — I'll keep calling them vectors below. You might think of various maps, sets and other accelerating structures, but those too are preferably built on top of vectors. Why so? Vectors are easy to understand, convenient for a large number of tasks, especially where the amount of data is unknown in advance or roughly known. But, as you understand, you have to pay for everything, and you pay with performance, of which, as usual, there's never enough. So using dynamic arrays has its limitations and quirks.
This is part of the "Game++" series:
- Game++. String interning
- Game++. Cooking vectors <=== You are here
- Game++. Dancing with allocators
- Game++. Juggling STL algorithms
- Game++. run, thread, run...
- Game++. Building arcs
- Game++. Unpacking containers
- Game++. Heap? Less
- Game++. Work hard
- Game++. Patching patterns
- Game++. while (!game(over))
- Game++. Bonus. Performance traps
std::vector and its analogues are often used to store everything from game objects such as entities to textures, network packets and tasks in schedulers. The upside is it's fairly simple to do and maintain. It's a container with sequentially allocated memory that can store an arbitrary number of elements. Each time the capacity grows, the vector allocates a new block of memory for the new size and copies the old elements there. There are pitfalls here too, related to elements that need copy-operation support, which can turn into a rather non-trivial task when some classes can't be copied at all.
Memory allocation

The standard says nothing about allocating memory for an empty array. When you create a std::vector, a block of memory big enough to hold some initial number of elements may be allocated. The size of this block can vary depending on the compiler and STL implementation. For example, that's what Nintendo's std::vector implementation does — it always allocates room for 4 elements when a vector is declared.
From the compiler's point of view, if we've declared such an array, in most cases it'll be filled, so why not do it right away. In principle this is a fairly good strategy, with one small exception: it'll work well only on the Nintendo platform, which has a separate allocator for small sizes up to 128 bytes; if you want more — welcome to the usual slow allocator, or write your own.
When the number of added elements exceeds the current capacity, std::vector increases the size of the allocated memory block. Usually the capacity grows by a factor of N, but again the exact value of the growth factor depends on the implementation. Some implementations may use a growth factor that depends on the current number of elements to minimize the overhead of reallocation, others rely on a constant factor.
When the capacity grows, all existing elements are copied to the new memory block. This can be an expensive operation, especially if the elements have complex constructors or destructors. Since most vector implementations use dynamic memory, this leads to its fragmentation, especially on resource-constrained systems such as consoles.
After the capacity grows, part of the allocated memory remains unused, to avoid frequent reallocation when adding new elements. It's a trade-off between memory efficiency and performance. This is especially pronounced at large sizes and with automatic management of vector capacity growth. Roughly, with an actual 100 elements in a vector, memory might have been allocated for 150–200 elements, which, with thoughtless use of vectors, ultimately leads to the question: where's the memory money, Lebowski?
Not all vectors are equally useful

Well then, enough downsides for the fastest and most popular container in gamedev? Let's see how to get rid of them. Completely, of course, we won't — games have become really memory-hungry, and often even a 2 MB stack per thread isn't enough. Before moving on and looking at various tricks, let me quote one legendary developer here:
Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%.
You've most likely heard its short version:
Premature optimization is the root of all evil.
I.e. don't mess around without first analyzing your code in a profiler, you'll only waste time.
When designing our logic, we often want to get a single composition (linear, multidimensional) in arrays, to have good cache locality, fast access and processing. Contiguous placement of data in memory is very good for speed, which makes this kind of std::vector the most efficient compared to the others. It looks something like this:
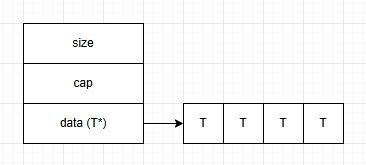
But because of the size and dynamic nature of objects, you more often end up with a double composition. However, in terms of placement in memory, a std::vector of std::vector is not an extended version of a multidimensional array in C++. The first is stored in one contiguous memory block, whereas the second is not. Roughly like this:
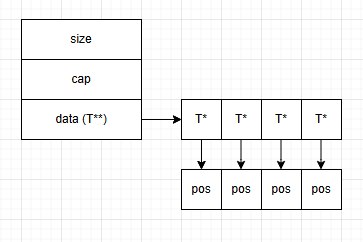
The double, or cascaded, std::vector structure has a memory layout similar to std::deque, which is a practically guaranteed CPU cache miss without extra effort. Processors already work more or less well with double or triple pointers, but with a higher pointer dimensionality the speed drops catastrophically. Moreover, and this is more critical, the cascaded std::vector structure requires many memory-allocation operations, whereas a single allocation is enough for a multidimensional array. Unfortunately, single composition isn't always achievable without a crowbar and some swearing, so the second option shows up much more often.
When developing software, especially where high performance is required, memory allocation is a serious constraint. Last year Sony rolled out a preview requirement that fps must not drop below 60 even in heavy scenes (it supposedly degrades the user experience), which gives us about 16 ms to prepare a frame.
A system call for memory allocation takes 1–10 ns if there was no collision with another allocation, when the time creeps up toward 40 ns, or toward 120 ns if a call to operator new or malloc() led to a system call to grow the heap, which in turn involves switching to kernel mode and a possible stall in the thread. There are, of course, specialized allocators for games and real-time systems like TLSF or jemalloc; if anyone's interested, there's an interesting article on the topic right here on Habr (https://habr.com/ru/articles/486650/) by @Spym.
As you can see, even a single memory-allocation operation can become a bottleneck if it runs inside frequently called logic. In games, dynamic memory allocation is in most cases forbidden — 95% of the time such code gets rejected at review. Without solid reasons you can't allocate memory wherever you like. Everything that can be allocated must be allocated before the level starts.
std::array

The first thing to consider if you want speed but don't want to bother writing your own classes is the standard C++ array. It has exactly N elements that are initialized on creation; this is of course not as convenient as a vector, which can have a variable number of elements and doesn't fire ctors at startup. On top of that we'll have to track the size ourselves via another variable. And array calls the constructor of its elements, which can also hurt perf. Inconvenient, but in a pinch, when there are no other alternatives, it works fine. std::array is just a static C++ array extended with STL capabilities. The size of a std::array is always N, and it's a static value determined at compile time.
std::vector vec = {} // 1, 2, 3, 4, 5 std::array vec = { 0 };
int vec_size = 0;What promiscuous relationships with vectors can cost you
#include <cstdint>
#include <array>
#include <vector>
static void VectorLoop(benchmark::State& state) {
for (auto _ : state) {
std::vector<int> vec = {0};
for (int i = 0; i < 5; ++i) {
vec.push_back(i);
volatile int x = vec[i];
benchmark::DoNotOptimize(x);
}
}
}
static void VectorLoopCached(benchmark::State& state) {
for (auto _ : state) {
std::vector<int> vec = {0};
vec.reserve(5);
for (size_t i = 0; i < 5; ++i) {
vec.push_back(i);
volatile int x = vec[i];
benchmark::DoNotOptimize(x);
}
}
}
static void ArrayLoop(benchmark::State& state) {
for (auto _ : state) {
std::array<int, 5> arr = {1, 2, 3, 4, 5};
for (size_t i = 0; i < 5; ++i) {
arr[i] = i;
volatile int x = arr[i];
benchmark::DoNotOptimize(x);
}
}
}
static void EmptyLoop(benchmark::State& state) {
for (auto _ : state) {
std::array<int, 5> arr = {1, 2, 3, 4, 5};
for (size_t i = 0; i < arr.size(); ++i) {
volatile int x = arr[i];
benchmark::DoNotOptimize(x);
}
}
}
BENCHMARK(VectorLoop);
BENCHMARK(VectorLoopCached);
BENCHMARK(ArrayLoop);
BENCHMARK(EmptyLoop);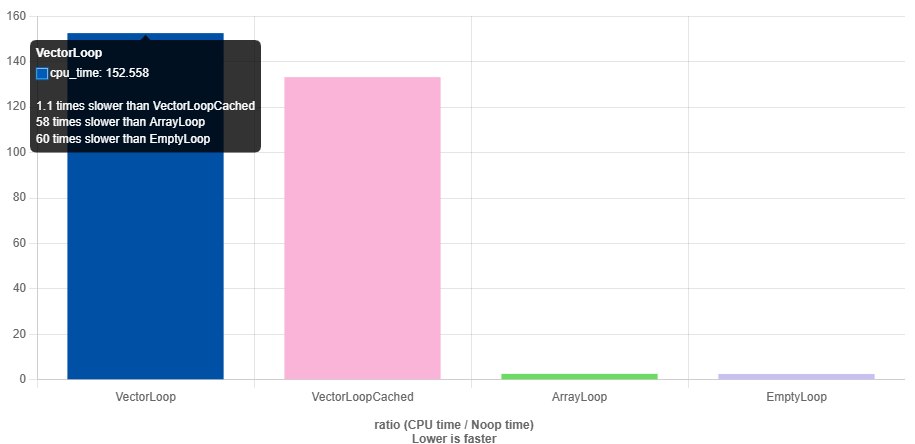
https://quick-bench.com/q/ScPhKA9CEtFcZp4DLLgTVBhFVfU
But you can't replace everything with array either — we once ran into problems porting a game from PS4 to Nintendo Switch. There was some code with, say, 20 ifs, and a temporary object was created in each branch. The code worked perfectly on PS4, but on the Switch it took a 21st if with its own temporary object. On the PlayStation the stack was 2 MB, and calling this function had already consumed, say, 460 KB. But on the Switch the stack couldn't be larger than 480 KB on any thread, and to exhaust the stack completely it was then enough for someone to put another 20 kilobytes or so on the stack.
In general 20 KB on the stack is peanuts from a game programmer's point of view. You might say that 20-kilobyte objects "good developers won't allocate on the stack" — okay, but will ten 2-kilobyte ones? That's to the question of where 20-kilobyte objects on the stack and two-megabyte thread stacks come from — just look at the example above. Swap std::vector for std::array and there go 128 KB; the things one does for speed. Yes, not always pretty, but fast and with song and dance during debugging.
static_vector

The inconveniences of working with std::array led to developers writing — and still writing — their own vector implementations that can live on the stack. If we keep improving the example from the previous paragraph, we get a class that, thanks to a certain structure, can store data locally (inside the object).
If we know that the size of such a vector won't exceed N, we can use that fact as a basis and replace a dynamically allocated vector with a statically allocated one. In game engines such a class, out of the need to optimize frame time, appeared almost immediately — in EASTL/Boost/Folly and other frameworks it shows up around 2014–15, and the standard library still doesn't have it. There are proposals for such a class, but they didn't even make it into the C++26 standard. static_vector eliminates most cases of memory allocation in functions, but you pay for it with huge 2 MB+ stacks, and even that's not always enough.
In the standard library we can use a pmr::vector with our own allocator that won't let it allocate more memory than it was given at design time (example below) — though this isn't always convenient. There's still a fallback to the heap, but the buffer is sized so the assert doesn't fire. The allocator is very simple and assumes the developer using it knows what they're doing. It has one quirk; if you find it, write in the comments.
// Initial allocations come from a fixed buffer, with later allocations just doing new / delete
// Pass a type and a count that will typically be used in the allocations for sizing the fixed buffer
template <typename T, size_t COUNT, size_t FIXEDSIZE = COUNT * sizeof(T)>
struct FixedMemoryResource : public std::pmr::memory_resource
{
virtual void* do_allocate(size_t bytes, size_t align) override
{
// Check if free memory in fixed buffer - else just call new
void* currBuffer = &mFixedBuffer[FIXEDSIZE - mAvailableFixedSize];
if (std::align(align, bytes, currBuffer, mAvailableFixedSize) == nullptr)
{
assert(false && "allocate more that expected");
return ::operator new(bytes, static_cast<std::align_val_t>(align));
}
mAvailableFixedSize -= bytes;
return currBuffer;
}
virtual void do_deallocate(void* ptr, size_t bytes, size_t align) override
{
if (ptr < &mFixedBuffer[0] || ptr >= &mFixedBuffer[FIXEDSIZE])
{
::operator delete(ptr, bytes, static_cast<std::align_val_t>(align));
}
}
virtual bool do_is_equal(const std::pmr::memory_resource& other) const noexcept override { return this == &other; }
private:
alignas(T) uint8_t mFixedBuffer[FIXEDSIZE]; // Internal fixed-size buffer
std::size_t mAvailableFixedSize = FIXEDSIZE; // Current available size
};There are plenty of static_vector implementations on GitHub, you'll easily find one for your needs; if you're curious, for my project I use this one github.com/dalerank/Akhenaten/.../svector.h (custom, with minimal dependencies — Boost/EASTL/Folly drag in way too many of their own headers). The further development of the static-vector idea became the hybrid vector.
hybrid_vector

In terms of memory, a hybrid_vector is a static_vector that can allocate room for any number of elements, but if that number is less than some threshold, it uses an internal structure for it.
A similar effect powers the small-string optimization (SSO) by Alexandrescu — the class's own member variables, interpreted as a byte array, are simply used as the internal buffer. A string object has to store a pointer to the string buffer, but a pointer with a 64-bit address can itself hold up to 8 characters without allocating memory. A typical string implementation also stores the size, capacity, sometimes a checksum, and the pointer to the buffer. Together, these fields can be used directly to store the string's internal buffer if the string size fits the constraints and doesn't exceed, say, 16+ characters.
If the data is created temporarily on the stack — for example, as local variables of a function that holds intermediate computation results — then a hybrid_vector can place all its elements locally, without resorting to dynamic memory allocation, just like static C++ arrays. Roughly, we know that NPCs usually use no more than two kinds of weapons, but stormtroopers might also lug around a machine gun; then it's more profitable to give all NPCs a hybrid_vector and keep all the data inside the class, while the stormtroopers get a dynamically allocated chunk of memory. But since, say, only 1 in 10 is a stormtrooper, we lose room for only two guns per NPC and get fast handling of NPC parameters.
Using a hybrid_vector comes with additional design costs. There are situations where it may bring no benefit at all.
- No reasonable "small" number N — bloating the class data isn't free either.
- The size is often much smaller than N, when most cases need less memory than the buffer allocates; here too you have to watch memory allocations carefully, but they're much easier to control than the standard classes, because you can always attach custom metrics or counters.
- Large elements. If elements take a lot of memory, the benefit of data locality is nullified by the increased memory footprint, and then the very reason we came up with this class — improving cache locality — gets smeared out, so there's no good gain, and the speed becomes comparable to heap-allocated arrays.
But here again it all depends on the algorithm and the hardware: on old mobiles and consoles a gain was observed up to about half a kilobyte on the stack, then there was a speed degradation, and somewhere around 16 KB it matched the heap in speed. On modern processors this no longer matters as much, the main thing is that the stack itself is big enough.
In the standard library, since C++17, we got the ability to emulate a hybrid_vector via allocators:
char buffer[64] = {}; // a small buffer on the stack
std::pmr::monotonic_buffer_resource pool{std::data(buffer), std::size(buffer)};
std::pmr::vector<char> vec{ &pool };But here too you have to be careful, because even vendor implementations can contain such gotchas that you'll have to rewrite a lot of code. As happened with a certain four-letter Japanese company that shipped its latest SDK, and our fps dropped by a third. Just yesterday it was a steady 60, and after the update 40–45 — the PM in horror, the programmers in shock, and the tech lead... the tech lead on vacation.

The code below simply skips over the first buffer and happily goes to system memory for an allocation, ignoring the static buffer. And who needs a hybrid_vector like that, which is no different from a std::vector?
There he is, that sneaky type of civilian appearance! (c)
class monotonic_buffer_resource
: public memory_resource
{ // pool optimized for quick allocation, slow or no deallocation
typedef _Mypoolalloc _Myalloc;
typedef _STD list<_Mon_block> _Mylist;
.....
virtual void *do_allocate(size_t _Bytes, size_t _Bound)
{ // allocate from blocks
if (_Free_space.empty()) // ensure one non-allocated entry
_Free_space.push_front(_Mon_block(0, 0));
if (_Initial_size == 0)
_Initial_size = _MONOTONIC_INITIAL_SIZE;
_Initial_size = _Roundup(_Initial_size);
_Bytes = _Roundup(_Bytes);
for (; ; )
{ // find aligned space, or add more blocks
for (_Mylist::iterator _It = _Free_space.begin();
++_It != _Free_space.end(); ) <<<<<<<<<<<<<<<<<<<<<<<<<<< ++It
{
uintptr_t _Current_offset_addr = (uintptr_t)(_It->_Ptr + _It->_Offset);
char *_Next_aligned_addr =
(char *)((_Current_offset_addr + (_Bound - 1)) & ~(_Bound - 1));
if (_Next_aligned_addr + _Bytes <= _It->_Ptr + _It->_Bytes)
{ // room for aligned storage, return its address
_It->_Offset = (_Next_aligned_addr + _Bytes) - _It->_Ptr;
return (_Next_aligned_addr);
}
}
// add more storage
size_t _Next_size = _Free_space.size() <= 1 ? 0
: _Free_space.back()._Bytes;
do { // add one or more ever larger blocks
if (_Next_size == 0)
_Next_size = _Initial_size;
else if (2 * _Next_size < _Next_size)
_Next_size = _Bytes; // last try if overflow
else
_Next_size *= 2; // double after first block
_Free_space.push_back(_Mon_block(_Next_size, _Bound,
upstream_resource()->allocate(_Next_size, _Bound)));
} while (_Next_size < _Bytes);
}
}We had to change every place in the code where monotonic_buffer_resource was used to a custom one. For comparison you can look at the canonical implementation for clang llvm-project/.../memory_resource.
So there you go — don't trust vendors bearing SDKs!
Conclusion
In a certain sense you can trace a dependency from vector to array, where performance increases at the cost of reduced flexibility (or increased memory consumption). In most cases the full flexibility of vector isn't needed, and it's used as a convenient but mindless default choice that gives access to the entire STL arsenal. Behind great convenience hides no less responsibility; lately not all developers even know how std::vector works under the hood and what the quirks of using it are.
Interesting materials:
← All articles