
This isn't a standalone article but a continuation of part 1 on the theory of objects in C++ — why objects in C++ are the way they are. I also publish all finished chapters on GitHub in English and Russian. Let's keep digging into C++ theory…

Object identity deserves a separate discussion, because in the real world concrete entities have identity, and Socrates remains Socrates regardless of whether he dyed his hair, changed his address, or died, while a state remains the same state even if it changes its flag, its constitution, or the size of its population.
To reflect this in a program, objects representing concrete entities need their own definition of identity, separate from current state. A convenient way to introduce such identity is to make some identity token, a unique value that expresses "who this is" rather than "what state it's in right now." Such a token can be, for example, the object's address in memory, an index in an array, or an employee number in an HR system — and by checking equality of identity tokens we are effectively checking the sameness of objects: the same object or different ones.
Over the lifetime of a program a concrete object may change its identity tokens, because it may be moved to a different region of memory, shuffled from one container to another, or assigned a new identifier, but the logical identity is preserved as long as we maintain a mapping between the "old" and "new" token.
Finally, it's worth drawing a clear line between equality of objects and their sameness. Two objects of the same type are equal if their states are equal as values: two std::string both holding "hello" are equal even if they sit in different places in memory and have different internal buffers; two std::vector<int> holding identical sequences are equal as sequences of values.
In this case it's natural to say that one object is a copy of another, and any changes made to one don't affect the copy. The equality check here relies on a value model, not on addresses, whereas sameness answers a different question — "is this the very same object, or just another object with the same state?".
In early C++ compilers and runtimes the question of equality and sameness was tightly bound to how copying and moving were implemented, and old implementations could unexpectedly "share" internal buffers between objects — for example std::string via copy-on-write — and you had to be careful about what exactly "a copy" meant; but as the standard and its implementations evolved, compilers and libraries became much stricter in treating equality by state and sameness by identity, which made reasoning about correctness easier.
// GCC before C++11 with COW strings:
std::string s1 = "hello";
std::string s2 = s1; // The buffer is NOT copied
// s1 and s2 point at ONE buffer in memory
// Internally the reference count = 2
// On modification:
s2[0] = 'H'; // Only NOW the buffer is copied (Copy-On-Write)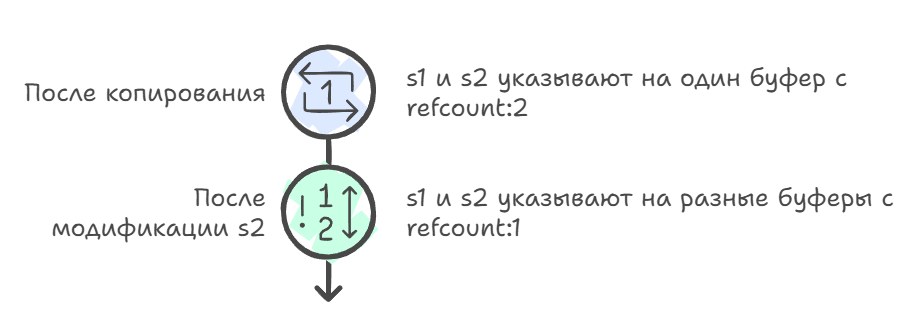
And with the arrival of new code-optimization techniques, it turned out that such a token may not exist at all, and the address stops being a reliable marker of identity, because an object may have no stable address at all throughout its lifetime, existing now in memory, now in registers, now as a constant baked into the code. Moreover, with move semantics in C++11 it became obvious that an object's address can change when it's moved from one container to another.
// C++ code:
struct Point { int x, y; };
void foo() {
Point p;
p.x = 10;
p.y = 20;
use(p.x + p.y);
}
// Without optimizations (the object lives in memory):
; %p = alloca Point
; store 10, p.x
; store 20, p.y
; load p.x, load p.y
// After optimizations (the object became values in registers):
; %x = 10
; %y = 20
; %sum = add %x, %y
; (there is no Point object in memory at all)
// here come the problems
Point p; ? no identity tokenThe simplest example of losing the address token is with arrays: you can store a pointer to a std::vector element and treat it as an identity token, but any operation that triggers a reallocation invalidates all pointers, and you have to use indices or iterators that stay stable relative to the order of elements but not to their physical location — and that's already a completely different model of identity, where "who this is" is defined not by "where it sits" but by "what number it is" or "how to get to it."
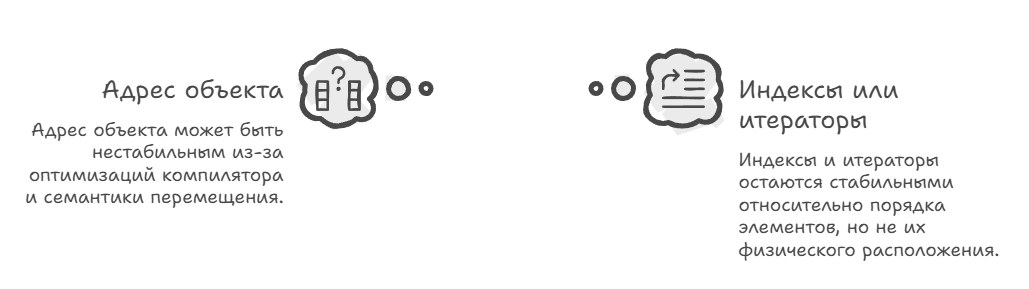
In modern game systems the identity token increasingly becomes an explicitly introduced value, independent of the address: in popular ECS architectures each object gets a unique numeric identifier at creation, and this ID stays unchanged regardless of how the object's components move in memory; in databases primary keys play the same role, letting you reference a record independently of its physical location on disk; and in distributed systems UUIDs or GUIDs are used to guarantee uniqueness without central coordination. All these approaches share one idea: the identity token must be a stable value that survives any moves, copies, and transformations of the object, and which can be safely stored, passed, and compared without fear that the compiler's optimizer, the garbage collector, or a data reorganization suddenly makes it invalid.
But it's useful for us to keep a simplified picture in mind: memory (addresses and words), value (the interpretation of a sequence of bits), object (the place in memory) where this value lives, and the data type as the notion of how we store, read, modify, and compare those bits.
Procedures
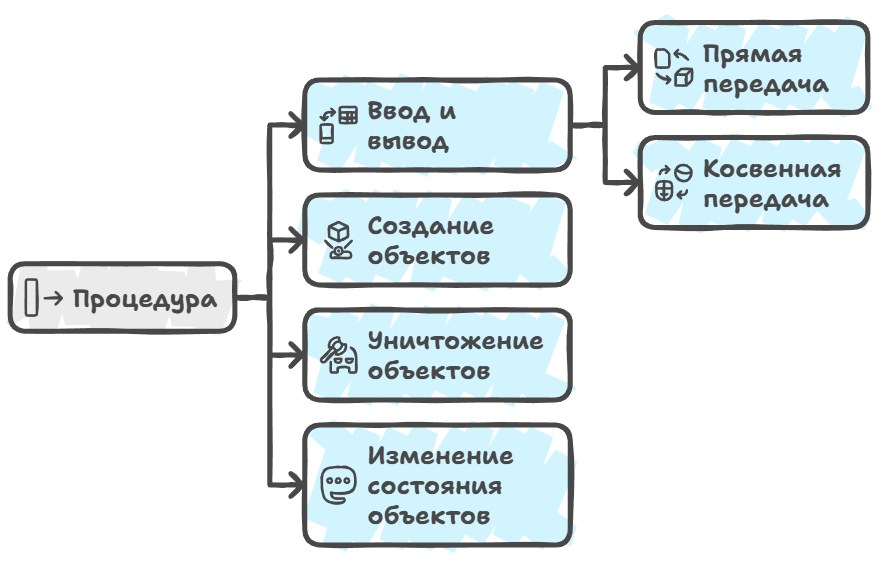
When we move from values and objects to the behavior of a program — and to what actually makes a program a program — another fundamental category enters the stage: procedures. In ordinary C++ this is just a function, but in a more general sense we can say a procedure is some sequence of rules that changes the state of the objects it works with, and sometimes also creates new objects or destroys old ones.
Historically compilers started with a very primitive understanding of procedures: in early Fortran and the first versions of C a procedure was just a named fragment of code with a fixed set of arguments, and all the "magic" was in correctly generating its entry and exit (the prologue and epilogue), saving registers, and organizing the stack.
int sum(int a, int b) {
return a + b;
}
int main() {
return sum(2, 3);
}
// simplified, everything goes through the stack
push 3 ; argument b
push 2 ; argument a
call sum
sum:
push bp
mov bp, sp
mov ax, [bp+4] ; a
add ax, [bp+6] ; b
pop bp
ret
// characteristics
- all arguments live in memory
- access via bp/fp
- every call is an explicit stack frame
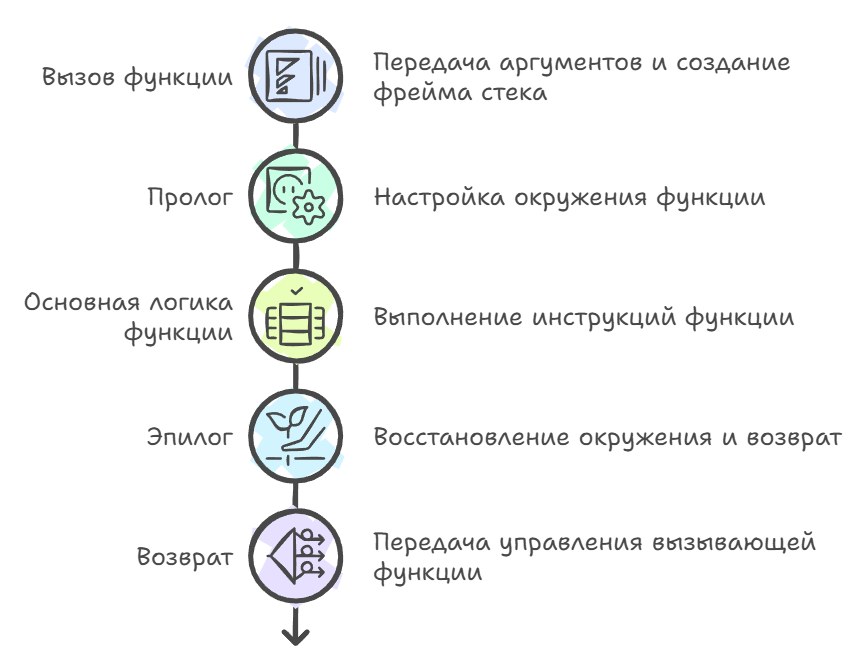
- simple, but slow overall and generates many memory accessesThe call stack itself is just a region of memory that grows and shrinks as the program enters and leaves functions, and each function call creates a new frame on the stack — a stack frame or activation record — that contains all the information needed to execute that particular instance of the function: local variables, arguments, the return address, saved register values, and possibly additional housekeeping data like a pointer to the caller's frame or padding for alignment.
When the compiler generates code for a function call, the first thing it has to decide is how to pass the arguments, and here the calling conventions come into play, dictating whether the first few arguments are passed through processor registers for speed and the rest placed on the stack, or whether all arguments go on the stack — slower but simpler to implement and debug — and historically different architectures and compilers chose different strategies.
// simplified, fastcall
mov ecx, 2 ; a
mov edx, 3 ; b
call sumreg
sumreg:
mov eax, ecx
add eax, edx
retThe prologue runs right after entering the function and before its main logic begins, and its job is to set up the working environment: save the values of those registers the function intends to use but which by convention must be restored before returning (callee-saved registers), allocate space for local variables, and set up a special register that will point to a fixed point inside the frame and let it address local variables and arguments at constant offsets regardless of how the stack pointer changes during the function's execution. In classic x86 the prologue looked like saving the old base-pointer value and setting the new pointer to the current top of the stack, and this sequence became so standard that processors even got a dedicated instruction doing all of it in one go, though in practice compilers rarely use it.
Allocating memory for local variables on the stack in the prologue isn't just subtracting a number from the stack pointer — it's also an optimal-placement problem: the compiler has to decide in what order to place the variables, how to align them, and whether the same region of memory can be reused for different variables that don't live at the same time, which saves space in the stack frame.
Early compilers solved this very straightforwardly: each variable got its own fixed slot, the frame size was the sum of the sizes of all local variables plus alignment, and there was no optimization; but as program complexity grew, algorithms like graph coloring appeared and started being applied to stack-variable placement too, allowing variables with non-overlapping lifetimes to be laid on top of one another.
The function epilogue does the reverse, restoring the stack pointer to the state it was in before the call and loading the saved values back into registers. Then it executes the return instruction, which pops the return address off the stack and hands control back to the caller — and here too there are subtleties, because different calling conventions distribute responsibility for cleaning the arguments off the stack differently. In cdecl the caller does it after the return, which lets you support functions with a variable number of arguments but requires generating extra code, whereas in stdcall the callee does the cleanup before returning, which saves code size but makes a certain kind of function call impossible; and it's exactly this difference that led to compatibility problems between different library versions, when code compiled with one convention was called from code expecting another, and the stack got corrupted, leading to crashes long after the incorrect call.
Modern compilers have moved far beyond the simple model of "allocate space, call the function, free the space" toward yet another system with its own theory and optimizations.
int sum(int a, int b) {
return a + b;
}
int main() {
return sum(2, 3);
}
// simplified, debug version
mov edi, 2
mov esi, 3
call sumreg
// sumreg, debug
; a → edi, b → esi
add edi, esi
mov eax, edi
ret
// sumopt, release
mov eax, 5
ret
// characteristics
- registers are the main path for passing data
- the stack as a fallback and for large objects
- the compiler can remove the call entirely
- or remove the frame and inline the execution at the call site
- or do the call and keep everything in registers
// bottom line
- a procedure ≠ necessarily a stack frame
- an argument ≠ necessarily a memory access
- a call ≠ necessarily a call instructionArgument passing
As languages and compilers evolved, it became clear that the key question here is not so much syntax as exactly how a procedure interacts with objects: which ones it reads, which it modifies, which live only for the duration of the call, and which outlive many calls and even the entire program. If we try to break this interaction into clear categories, we can single out four groups of objects that practically any procedure deals with. First, this is "in and out / in-out," that is, objects passed into and out of the procedure either directly or indirectly.
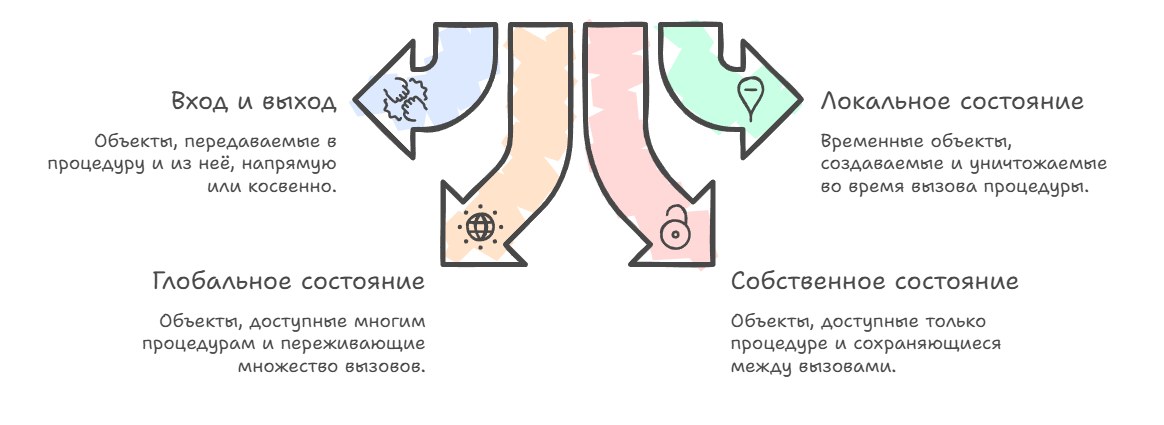
Directly is when you write int f(int x) and the compiler passes the value x via registers or the stack and then returns the result, say, in a register too; indirectly is when you pass a pointer or reference, like void increment(int* p), and the procedure works with the object not as a copy of the value but as the original in memory.
Second, there's local state: temporary objects created at the start of a procedure call, living on the stack or in registers, adapting to the algorithm's needs and destroyed when the procedure finishes. If in a function void foo() you declare int tmp = 0; std::vector<int> v(10);, then both tmp and v are part of this procedure's local state: it needs them to work, but no one outside knows about them or should.
And global state: objects accessible not only to this procedure but to others as well, and across many calls — these are global variables, static fields, or objects in dynamic memory referenced from different parts of the program.
And finally, there's the procedure's own state, that is, objects accessible only to it (and possibly closely related functions) but preserved between calls. The simplest example is a static variable inside a function: you can write
void counter() {
static int n = 0;
++n;
std::cout << n;
}and then n lives as long as the program lives, but only counter can use it; for everyone else it effectively doesn't exist — and this demonstrates the typical pattern of "hidden" procedure state, which appeared back in old C long before classes.
In, Out, InOut
To speak more precisely about a procedure's behavior, we need to introduce one more distinction: which objects count as its inputs, which as outputs, and which as both. If a procedure only reads an object's value, never changing it, then for the procedure that object is a pure input; if instead the procedure creates an object, writes data into it, or destroys it without looking at its previous contents, then such an object acts as an output and its initial state doesn't matter, only the new one does.
/* ═══════════════════════════════════════════════════
PURE INPUT / the function only reads the object
═══════════════════════════════════════════════════ */
// len doesn't change the array, arr is a pure input.
// The compiler may hoist the call out of the loop (CSE/hoisting),
// cache the result, reorder it relative to other
// calls that also only read.
size_t len(const int *arr, size_t n) {
size_t count = 0;
for (size_t i = 0; i < n; i++)
if (arr[i] != 0) count++;
return count;
}
void pure_in(void) {
int data[] = {1, 0, 3, 0, 5};
// The compiler sees that data doesn't change between calls →
// it can compute len() once and reuse it.
printf("len=%zu, len=%zu\n", len(data, 5), len(data, 5));
}/* ═══════════════════════════════════════════════════
PURE OUTPUT / the function creates or fully fills the object,
the previous contents are not read
═══════════════════════════════════════════════════ */
// The initial state of dst doesn't matter at all — it's a pure output.
// The compiler can eliminate the preceding write to dst (DCE):
// if fill() comes right after it, the old data is overwritten anyway.
void fill(int *dst, size_t n, int value) {
for (size_t i = 0; i < n; i++)
dst[i] = value; // only a write, no read
}
void pure_out(void) {
int buf[8];
buf[0] = 42; // ← the compiler may remove this write (DCE):
// fill() below overwrites the whole array
fill(buf, 8, 0);
printf("buf[0]=%d\n", buf[0]);
}The most interesting case is when an object is both read and modified: for example, a counter passed by reference that the function increments, or an array element that is first checked against some condition and then updated. Such objects act as the procedure's in/out, and they are most often the source of complex effects and bugs if the programmer doesn't fully realize who in the program has the right to change their state.
// --- A counter passed by reference ---
// counter is first read (to increment), then written.
// Two calls to increment() are NOT equivalent to one increment_by_2(),
// if between them there's another thread or signal reading counter.
void increment(int *counter) {
(*counter)++; // read + write: a typical in/out
}
// --- An array element: check + update ---
// The function first looks at the old value (input),
// then writes the new one (output). The order of operations is critical.
void cap_and_mark(int *value, int limit) {
if (*value > limit) // read ← input
*value = limit; // write ← output
}
// --- The classic accumulate: in/out in its purest form ---
// sum is read on every iteration and immediately written.
// The compiler CANNOT swap the iterations around or
// parallelize without an explicit hint (OpenMP reduction etc.),
// because each iteration depends on the result of the previous one.
void accumulate(const int *arr, size_t n, int *sum) {
for (size_t i = 0; i < n; i++)
*sum += arr[i]; // *sum: read → modify → write
}In early compilers the analysis of these categories was almost entirely on the programmer's conscience and the compiler simply took the code as is, but modern compiler optimizers actively analyze which variables are only read, which are written, and where side effects are possible, and on that basis decide which calls can be changed (reordering, cse, dce), which transformations are allowed, and which would violate the expected semantics.
// restrict tells the compiler: the pointers dst and src don't overlap.
// Without it the compiler must assume that dst and src may
// point to the same region of memory (aliasing) → vectorization is forbidden.
// With restrict — it can be unrolled into SIMD instructions.
void add_arrays(int * restrict dst,
const int * restrict src,
size_t n)
{
for (size_t i = 0; i < n; i++)
dst[i] += src[i]; // dst: in/out; src: pure input
}
// __attribute__((pure)) — an explicit GCC hint:
// the function has no side effects and depends only on its arguments.
// The compiler can eliminate repeated calls (CSE) and
// reorder the call relative to code that doesn't touch memory.
__attribute__((pure))
int dot_product(const int *a, const int *b, size_t n) {
int result = 0;
for (size_t i = 0; i < n; i++)
result += a[i] * b[i];
return result;
}The computational basis
Moving from procedures to the idea of a computational basis, you have to understand which operations your type supports at all. For any value type you can define some minimal set of procedures from which, in principle, all other operations over it can be built; such a set is called the type's computational basis.
For example, for unsigned k-bit integers you can take the operations "get zero," "check equality," and "go to the next value," and theoretically from them you can implement addition, multiplication, and comparison, just as very long sequences of calls to "next" and checks.
But here the notion of efficiency comes into play: a basis is considered efficient if any procedure built on top of it can be implemented no worse than on any other reasonable basis. In the example (below) with the "next" operation everything is bad: adding two k-bit numbers by repeatedly incrementing one of them requires on the order of 2^k steps in the worst case, that is, it's deliberately slow, whereas implementing addition at the level of machine instructions runs in a fixed number of cycles independent of the argument values.
Historically, if you look at the evolution of processor architectures and compilers, you can see how the set of base operations was gradually expanded precisely for the sake of efficiency: from the first machines with a very limited instruction set, where complex operations had to be emulated with long sequences of elementary steps, to modern architectures with a rich system of arithmetic and logic commands, for which compilers can generate specialized code and vectorized versions of algorithms.

A short historical digression on how code seeped into silicon
1940s + 1950s: a minimal computational basis
ENIAC (1945) had no stored program at all; "instructions" were set with patch panels. The only operations: addition and subtraction over decimal digits accumulated in ring counters.
Manchester Mark 1 (1948) and EDSAC (1949) were the first stored-program machines. Instruction set: load/store, addition, shift, conditional jump. Multiplication was absent as a hardware operation and the programmer wrote a subroutine of addition loops.
IBM 701 (1952) IBM's first commercial scientific computer. Multiplication appeared but took ~40 machine cycles, and division around 80. Against addition (1 cycle) this was already a noticeable "basis optimization."
Division was implemented by repeated subtraction: the processor looped subtracting the divisor from a partial remainder and counting iterations.
Late 1950s + 1960s: hardware multiplication, division, addressing modes
IBM 704 (1954) the first mass computer with hardware floating point and hardware multiplication in a single instruction. Index registers made it possible to address arrays with a loop instead of manually substituting the address.
IBM System/360 (1964) the unification of all systems and one ISA for machines from desktop to mainframe. Over 100 opcodes; the modes
base + displacement,register indirectappearedPDP-8 (1965) 8 instructions in the ISA, but powerful addressing modes compensated for the scarcity and showed that "a small basis + smart modes" gives flexibility no worse than "a large basis."
CDC 6600 (1964) the first supercomputer with a pipeline and several functional units in parallel. Its Fortran compiler already did instruction scheduling so the pipeline wouldn't stall.
1970s: microprocessors, x86, coprocessors
Intel 4004 (1971) 4-bit, 46 instructions, no multiplication. A minimal basis in a silicon chip.
Intel 8080 (1974) 8-bit, instructions for BCD arithmetic appeared (
DAA,DAS) like adding decimal digits in a binary register. An example of expanding the basis for a specific application domain (accounting, cash registers).Intel 8086 (1978) 16-bit, 16-bit multiplication
MUL/IMULand divisionDIV. Added the operationsMOVS,LODS,STOS— effectively a hardware memory-copy loop, what previously would have required an explicit assembly loop.Zilog Z80 (1976) added
LDIR(block move) andDJNZ(decrement and jump if non-zero) — a hardware implementation of the "counted loop" pattern; another example of how a frequent software pattern "sinks" into hardware.Intel 8087 (1980, formally already crossing into the 1980s) added a coprocessor with 80-bit stack registers and the instructions
FSIN,FCOS,FSQRT,FYL2X. Trigonometry, which previously took hundreds of lines of library code, became a single command in silicon. The Fortran compiler immediately learned to emitFSINinstead of callingsin()from libc.
1980s: RISC and the "the compiler is smarter than microcode" philosophy
Berkeley RISC (1980) and Stanford MIPS (1981) academic projects that showed simple fixed-length instructions allow a long pipeline without stalls, while complex operations are better implemented in the compiler than in microcode.
SPARC (1987, Sun) the first major commercial RISC architecture. Sun's cc compiler did register allocation across function calls without writing to memory. The processor was specifically designed for Sun's compiler.
MIPS R2000 (1985) added a separate
DIVunit that worked asynchronously from the pipeline.ARM (1985, Acorn) a 3-address RISC ISA where the compiler could turn short if-branches into linear code without jumps — the grandfather of speculative execution and a crucial optimization for small branch predictors.
Intel 80386 (1985) 32-bit,
PUSHA/POPA,ENTER/LEAVEfor function prologues in a single instruction.
1990s: SIMD and expanding the basis "in width"
Intel MMX (1996, Pentium MMX) 57 new instructions, now eight 64-bit registers
mm0–mm7and onePADDBadded 8 pairs of bytes at once. Video codecs, audio, 2D graphics immediately picked up the new capabilities and it sped up code 4–8× when prepared properly.AMD 3DNow! (1998, K6-2) 21 instructions for 2×float32. Aimed at 3D-game geometry:
PFMUL,PFADD,PFRCPIT1(reciprocal-root approximation). Adapting a niche CPU-basis extension to a specific market.Intel SSE (1999, Pentium III) 70 instructions, eight new 128-bit registers
xmm0–xmm7. GCC got the-msseflag and began auto-vectorizing simple loops.SSE2 (2001, Pentium 4) added double-precision float and integer SIMD in xmm registers. Now compilers gradually move to SSE2 for scalar floating point.
x86-64 / AMD64 (2003, AMD Opteron) technically the 2000s, but rooted in the 1990s (the project started ~1999). Registers extended to 64 bits,
r8–r15added. SSE2 became a mandatory part of the computational basis.
2000s: 64-bit everywhere, cryptography, and SIMD expansion
SSE3 (2004, Prescott) added horizontal addition
HADDPS(adds neighboring lanes within a register), needed for complex arithmetic and convolution functions; under market pressure the code again moved into silicon.SSSE3 (2007, Core 2)
PSHUFBand byte permutation by a mask. One of the most powerful primitives: it allows implementing lookup tables and bit manipulations without branches; Intel's compiler uses it for LUT optimizations.SSE4.1 / 4.2 (2007–2008)
PMULDQ(32f×32f→64f multiply),PCMPESTRM(substring search in a string in a single instruction),CRC32; string algorithms and hash functions got hardware support in siliconVT-x / AMD-V (2005–2006) virtualization: the new instructions
VMXON,VMLAUNCH,VMEXIT. The computational basis expands not only for computation but for privileged management.
2010s: AVX, bit algebra, transactional memory
AVX (2011, Sandy Bridge) 256-bit
ymmregisters, 8 float32 or 4 float64 per cycle. Removed destructive operations; compilers learned to distribute subtypes across all registers.AVX2 (2013, Haswell) integer 256-bit SIMD, GCC with
-march=haswellbegan auto-vectorizing many more patterns.BMI1/BMI2 (2013) POPCNT can now count the number of set bits. The Hamming algorithm of ~15 instructions turns into 1 operation.
AVX-512 (2017, Skylake-X / Knight's Landing) 512-bit
zmmregisters (16 float32)TSX / RTM (2013) transactional memory:
XBEGIN/XEND/XABORT. An attempt to sink lock-free patterns into the computational basis, but disabled due to vulnerabilities.
2020s: matrices, scalable vectors, AI primitives
AVX-VNNI (2021, Alder Lake) —
VPDPBUSDand variations: int8/int16 dot-product with int32 accumulation. One call replaces an inner convolution loop, aimed at neural-network inference right on the CPU without a GPU.Intel AMX (2023, Sapphire Rapids) tile registers
tmm0–tmm7up to 1 KB each;TDPBSSDcomputes a whole block of matrix multiplication in a single instruction, which made it possible to expand the computational basis from "vector" to "matrix."ARM SVE (2016, implemented in Fujitsu A64FX 2019, Apple M4 2024) the vector length is not fixed in the computational basis, and one binary can run correctly on 128-, 256-, 512-bit and wider. The compiler generates the code once, and the hardware adapts to the data width.
You could, of course, say that subtracting two arbitrary numbers is also excess and can be implemented through addition with negation, and negation through subtraction from zero, but if you try to write real code with only the operations "+", "0", and "next," you'll find that many definitions become bulky and unreadable. So when we design an "expressive" basis, we add operations that are logically derivable from others, but whose practical usefulness from being explicitly present far outweighs the cost of growing the basis.
// ============================================
// MINIMAL BASIS (theoretically sufficient)
// ============================================
namespace MinimalBase {
using uint = unsigned int;
// Three primitives:
uint zero() { return 0; }
bool equal(uint a, uint b) { return a == b; }
uint next(uint a) { return a + 1; } // increment
// Everything else is built from these three operations:
// Addition via repeated increment - O(b) operations!
uint add(uint a, uint b) {
uint result = a;
for (uint i = zero(); !equal(i, b); i = next(i)) {
result = next(result);
}
return result;
}
// Multiplication via repeated addition - O(a*b) operations!
uint multiply(uint a, uint b) {
uint result = zero();
for (uint i = zero(); !equal(i, a); i = next(i)) {
result = add(result, b);
}
return result;
}
// Comparison via subtraction (via repeated decrement)
// O(min(a,b))
bool less(uint a, uint b) {
while (!equal(a, zero()) && !equal(b, zero())) {
a = a - 1; // here we need prev(), but it's not in the basis yet
b = b - 1;
}
return !equal(b, zero());
}
}That's how it turned out in the C++ standard too: formally the language could have been made very minimalist like its parent, but in practice most of us need operators like -, *, /, the checks <, >, and standard functions over numbers to express our thoughts clearly and concisely, while such an extended set lets the compiler translate them better into the corresponding machine instructions.
Compilers and libraries gradually enriched the basis of available operations: early versions of the standard libraries had fewer algorithms and fewer "built-in" operations over types, and programmers had to implement themselves what today is taken for granted, having everything they need at their disposal: from elementary numeric functions to complex sorting and search algorithms.
Modern compilers already live in a world where the computational basis for fundamental types is rich enough and well optimized, and their main task now is to use this basis as efficiently as possible without breaking the language's semantics. When you write a + b for integers, the compiler knows exactly which machine instruction to use, how to account for overflow, which flags will be set in the processor, and on that basis can build optimal command sequences. Now if you overlay the development of hardware onto the capabilities of languages, you get something like this:

50s: ENIAC → arithmetic (addition as the base operation)
70s: C → memory and pointers (address arithmetic)
90s: STL → iterators and abstract algorithms (operations instead of types)
2000s: SIMD → vectors (one operation over many data)
2010+: AMX / JAX → matrices and computation graphs (block and declarative operations)If, however, you create your own type, say BigInt or Rational, and define for it a minimal set of operations that is technically complete but not very expressive or efficient, then all the functions you write on top of this basis will inherit its shortcomings too: addition implemented as repeated increment will stay exponential, no matter how you optimize. So when designing your own types in C++ you effectively repeat the path of machine architects and compiler authors: you choose which operations to make basic so that expressing algorithms is convenient and the compiler can produce efficient code — and it's exactly here that the ideas of regular types and a careful choice of computational basis become not theory but a practical guide to designing good, predictable, and fast abstractions.
Regularity
Modern C++ wouldn't exist without regularity, which at first glance seems redundant. But we're used to writing code based on general notions and relying on comparison, copying, and assignment "somehow working at the level of the language and compiler." Behind regularity lies an idea that lets the compiler safely optimize code and lets us reason about it in mathematical terms, and this idea has its roots in Alexander Stepanov's fundamental work from the early 1990s.
/* ═══════════════════════════════════════════════════════════════
IrregularMatrix an IRREGULAR type for comparison.
Violates the equality axiom: a copy is not equal to the original
(identity instead of value equality).
═══════════════════════════════════════════════════════════════ */
class IrregularMatrix {
int* data_;
int size_;
public:
explicit IrregularMatrix(int n)
: size_(n), data_(new int[n]{}) {}
// The copy constructor copies the POINTER, not the data.
// After this two.data_ == one.data_ changing one changes two.
// This breaks regularity: the copy depends on the original.
IrregularMatrix(const IrregularMatrix& o)
: size_(o.size_), data_(o.data_) {} // <- deliberate bug
// operator== compares ADDRESSES, identical data is not considered equal.
// Regularity is broken and two objects with the same data != each other.
bool operator==(const IrregularMatrix& o) const {
return data_ == o.data_; // <- deliberate bug
}
};A regular type in the modern sense behaves like primitives such as int or double and supports correct equality, copying, assignment, and a default constructor in such a way that equal values stay equal after any operations, and copies remain fully independent of the original, and this predictability lets the compiler replace expressions with semantically equal ones without losing program correctness.
Regular functions, in turn, return equal results when applied to equal arguments, and this property, called regularity, underlies all the algorithms of the standard library — from sorting and searching to sequence transformations. The entire STL was built on the assumption that types in containers and algorithms behave as regular: equality is reflexive, symmetric, and transitive, copying creates an independent copy, and assignment doesn't change the original — and it's exactly this that made it possible to create a library where the same std::sort algorithm works correctly with int, with std::string, and with our user types, if they were designed properly.
// A template function works with ANY regular type.
// Stepanov called this "algorithms abstracted from the type."
// std::sort, std::unique, std::min_element are all the same.
template <typename T>
T midpoint(T a, T b) {
// Works correctly only if T is regular:
// we need (a + b) / 2 to equal what we expect.
return (a + b) / T(2);
}When we work with built-in types like int, double, or bool, we usually consider equality, copying, and assignment to be constant time, because they reduce to one or two machine instructions of comparison or register moves, but as soon as we move to composite objects the picture gets more complicated. We also expect an equality check to take time proportional to the total amount of data, including local fields; however, in practice this linear complexity isn't always guaranteed, and compilers use tricks to speed up such operations.
/* ═══════════════════════════════════════════════════════════════
A type where representational == behavioral
Trivial types (POD) with a fixed canonical
representation and precisely for them the compiler is allowed
to use memcpy/memcmp and generate a SIMD comparison.
═══════════════════════════════════════════════════════════════ */
struct Vec3 {
float x, y, z;
// We rely on bitwise equality: for Vec3 without NaN this is correct.
// The compiler can unroll into three FCMPE or one VCMP (NEON/SSE).
bool operator==(const Vec3& o) const = default; // bitwise
// Copying via memcpy guarantees regularity,
// which for a properly designed type entails behavioral identity.
Vec3(const Vec3& o) {
std::memcpy(this, &o, sizeof(*this));
}
Vec3(float x, float y, float z) : x(x), y(y), z(z) {}
};If we take a multiset (an unordered collection of elements with possible repetitions, e.g. a std::vector with duplicates), then such a type is no longer regular, but there are nuances. Inserting a new element is constant time, because we add the element at the end, but to check the equality of two such multisets you have to either sort both and compare lexicographically, which takes O(n log n), or for each element of the first set check its presence in the second accounting for multiplicity, which takes O(n²) in a naive implementation.
The standard std::unordered_multiset handles this better: its operator== works in O(n) on average but degrades to O(n²) with many hash-function collisions, and the standard explicitly allows this. If you start using such multisets as elements of another container where equality checks are needed for searching or hashing, performance drops sharply compared to types whose operator== works in O(1).
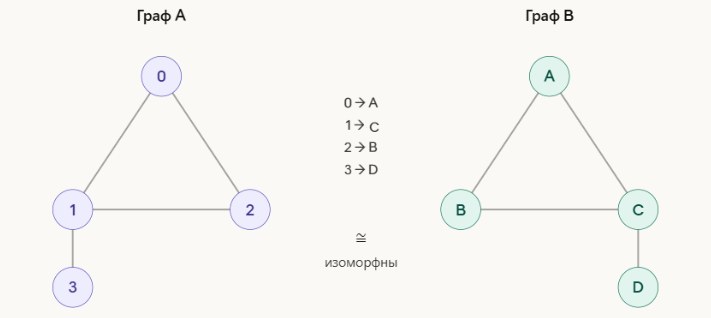
In extreme cases equality can turn out to be an NP-hard problem, for example if you need to check graph isomorphism. Graph A and graph B look different — different vertex names, different layout. But if you rename 0→A, 1→B, 2→C, 3→D, all edges match one to one. So the graphs are isomorphic: the same structure, just drawn differently.
To check isomorphism in the general case, you need to find the right correspondence among all possible permutations of vertices. For a graph of n vertices that's n! variants, and at n=20 that's already a gazillion operations. A fast (within reasonable time) algorithm that would work for arbitrary graphs hasn't been found so far, but it also hasn't been proven that none exists.
In such situations the programmer is forced either to give up full semantic equality, or to settle for representational equality and compare bits directly, which is fast but can give false positives for values that are semantically equal yet encoded differently.
/* ═══════════════════════════════════════════════════════════════
A typical compromise in real code:
store a canonical form to support regularity
Pattern: normalize on creation → memcmp is correct.
This is exactly how std::set, std::map are built,
═══════════════════════════════════════════════════════════════ */
struct CanonicalGraph {
int V;
std::set<std::pair<int,int>> edges; // stores {min,max} — the canonical form
void add_edge(int u, int v) {
if (u > v) std::swap(u, v); // normalization on insertion
edges.insert({u, v});
}
// Now isomorphic graphs with the same numbering are equal;
// identically encoded ones too.
bool operator==(const CanonicalGraph&) const = default;
};That's exactly why, when behavioral equality is too expensive or impossible to implement, you have to fall back to representational: two values are equal if their bit image is identical, and for composite objects this is often implemented via recursive field comparison or via memcmp on raw bytes.
Representational equality always entails behavioral equality, because if the bits match then the interpretation matches, while the reverse isn't always true; but in practice this is very convenient for copy and assignment constructors: if you implement them via byte-wise copying, you guarantee that the copy will be equal to the original by representation, and if the type is designed correctly, by behavior too.
Likewise, when full semantic equality is too expensive, you can use a structural order: lexicographic for sequences or by the first differing fields for structures, which lets you sort and search efficiently even when the true semantic order isn't available. However, not all objects allow copying or equality at all: if an object owns a unique resource like an open file, a network connection, or a GPU buffer, then neither copying nor assignment makes sense for it, and such types we classify as "non-regular" and use in special contexts where we explicitly spell out their semantics.
/*
Structural order instead of semantic
When the true "semantic" order is unavailable or expensive,
lexicographic / by-field is a practical alternative.
std::sort, std::map, std::lower_bound work with any
strict weak ordering, without requiring the "right" meaning.
*/
struct Version {
int major, minor, patch;
// Structural order by fields: first major, then minor, then patch.
// This is at the same time the "right" semantic order for versions —
// a rare case where structural and semantic coincide.
auto operator<=>(const Version&) const = default;
bool operator==(const Version&) const = default;
};
struct Document {
std::string author;
int year;
std::string title;
// Structural order: author → year → title lexicographically.
// The semantic order (by document "importance") is unavailable,
// but this is enough for std::set and std::map.
auto operator<=>(const Document&) const = default;
bool operator==(const Document&) const = default;
};In modern C++ the ideas of regularity finally got an official expression in the form of concepts, which literally embody in the language what Stepanov talked about back in the 1990s, and these decisions directly affect container design, where good types always strive for regularity. Solving the problems of regularity made it possible to get types like std::string_view, std::span, std::optional, which are designed so that equality reflects meaning rather than implementation details, and copying means logical duplication rather than shared ownership of resources.
But if a type is non-regular by nature and owns a unique socket, GPU buffer, or large file, then it's explicitly classified as an "object" type and not stuffed into value-oriented containers, or it's equipped with a weak equality model with clear documentation of what exactly it checks.
/*
Non-regular types with unique ownership of a resource
If an object owns a resource (file, connection, GPU buffer),
copying makes no sense. A move-only type expresses this explicitly.
The compiler will forbid accidental copying, raising a compile-time error.
*/
// Imitation of a GPU buffer — a unique resource
class GpuBuffer {
void* handle_;
size_t size_;
}For the compiler's optimizer, regularity is expressed as permission to reorder operations, replace a + b with b + a, or even cache the result, without side effects and without the ability to violate observable behavior.
Compiler developers took a long road to understanding these ideas, and in early C the notion of regularity didn't exist at all — the programmer simply relied on primitive types behaving predictably and composite structures behaving as written. But today we can write template<std::regular T> void process(T value); and the compiler can check at build time that the type meets all the requirements, including correct equality and copying, which radically simplifies debugging and makes code more reliable than in the era when all of this hung on someone's word of honor.
Conclusion
The road processor architects traveled from ENIAC to AMX, and the road C++ traveled from the first compilers to concepts, are parallel paths: from a minimally working set of operations to a rich, expressive, and efficient basis. When you design your own type (a class, an architecture, or an algorithm), you repeat this path in miniature: from a simple definition of what you can do with values at all, by creating base operations and stacking complex ones on top, and finally you decide how regular the type turns out to be, or you give up and admit that it's non-regular by nature. Long ago developers noticed that good types behave like mathematical objects, working predictably, independent of context, without hidden states and surprises. And thirty years later the language has finally grown up enough to express this idea directly through concepts. This is perhaps the best illustration of the fact that a good theory in programming sooner or later becomes practice.
← All articles