
This is the published version of the first chapter of the PragmatiC++ draft (part 1) — a book on pragmatic C++ that still makes sense a year later. The chapter source is open on GitHub.

Imagine for a moment that C++ isn't a set of strange keywords and linker errors, but just another way to talk about the world around us: about people, numbers, colors, events and cats. We're used to thinking of programming as something purely technical, where it's important to memorize the syntax, place the semicolons and "guess" what the compiler wants right now.
But if you ask yourself "what does a program even operate on?", it suddenly turns out that behind all those int, struct and template hide rather simple and understandable ideas: things, their properties, groups of similar things, and the rules by which some things turn into others.
And in trying to explain what objects, types and other fundamental concepts of computer science are, you inevitably have to go beyond purely technical language and talk about more general categories of ideas that humanity has worked with for thousands of years, and this is exactly where the words "entity," "kind" and "genus" come in handy.
When philosophers and logicians talk about abstract entities, they mean individual things that don't exist in space and time the way a table, a person or a computer does, but as something unchanging: for example, the number 13 or the color blue itself weren't born at some moment and don't "die" after some time; these aren't objects of the physical world but ideas we work with in our heads and in mathematics.
Before reading, it's better to watch the first two lectures by Konstantin Vladimirov, to refresh the basic concepts in memory a bit.
Entity
A concrete entity, on the contrary, is always tied to history, to the moment of appearance and the moment of disappearance: Socrates was once born and once died, any country as a political entity was created on a certain date, and although the country continues to exist, it's quite clear that someday it won't be there, or it may radically change.
At the same time you can talk not only about the entities themselves but also about their attributes, reducing the correspondence between a concrete entity and an abstract entity to a description of properties: the color of Socrates' eyes can be described as a concrete example of abstract color, the number of Germany's federal states as a concrete value of an abstract natural number. If at some moment we take a "snapshot" of a concrete entity, fixing the full set of its attributes here and now, we understand that over time individual attributes may change, but identity remains — and it's precisely identity, that very primitive but deep feeling of "it's still him," that lets us say that a person, a country or a program object continue to be themselves even though their properties change.
Next arises the need to somehow group entities, and here the notions of kind and genus take the stage, and each of these categories is also either abstract or concrete, and when we speak of an abstract kind, we describe the common properties of a whole family of abstract entities.
Thus the kind "natural number" covers all the individual numbers 0, 1, 2, 3 and so on (zero may not fall into the natural numbers and be treated as the empty set), the kind "color" defines all possible shades from dark blue to bright orange, and we can reason about them as something general without tying ourselves to a concrete instance. A concrete kind, on the contrary, describes a set of attributes for a family of concrete entities: when we say "person," we mean a concrete kind that includes all people with a certain set of characteristics like biology, consciousness and so on; when we say "parts of the world," we describe a concrete kind that includes Europe, America or Asia, each of which has borders, population, area and other attributes.
They differ as entities, but within the kind "person" or "part of the world" we can talk about recurring structural properties and model them in code as objects of one data type. An important role in this picture is played by the notion of a function, and here the mathematical definition moves over into programming almost verbatim: a function as a rule that, to some set of abstract entities called arguments and belonging to certain kinds, assigns another abstract entity called the result, belonging possibly to a different kind.
A classic example from mathematics would be the successor function, which to each natural number assigns the number following it, the function "n → n + 1" in terms of the natural kind. Another, more figurative example is a color-mixing function, which to two arguments of the kind "color" assigns a third color as the result of their mixing — and if you've ever written code that returns a new Color from two Colors, you were essentially implementing exactly such a function.
In programming we live inside this definition: any function call in C++ is the application of a rule to arguments that are concrete "imprints" of abstract entities, and the result becomes a new object that can also be regarded as a concrete embodiment of an abstract entity of a certain kind.
// Kind: natural number
using Natural = unsigned int;
// Successor function: n → n + 1
// A rule that assigns to each Natural the next Natural
Natural successor(Natural n) {
return n + 1;
}If we rise to the next level of abstraction and talk about genera, they let us speak not only of concrete values or even kinds, but of large classes of concepts.
Genus
A genus is a way to describe a set of different abstract kinds that are similar in some respect: for example, the genus "number" includes kinds such as "natural number," "integer," "real number," each of which has its own rules of existence, but we can reason about them as a number in general without specifying the kind; the genus "binary operator" includes both the arithmetic operations of addition and multiplication, and the logical operations "and," "or," and bitwise operations, but all of them obey the common schema "take two arguments and get a result."
A concrete genus, in turn, describes a set of different concrete kinds similar by some traits: "mammal" describes different concrete kinds like human, cat and whale, "biped" describes another classification that includes people, birds and perhaps some fictional creatures — and the same entity.
// Genus: a template - a rule over kinds
// This is already the level of "genera": Pair<T, U> isn't a concrete kind,
// but a rule that assigns a new kind to two kinds
template<typename T, typename U>
struct Pair {
T first;
U second;
};
// A function working at the genus level: for any kind T
// returns a pair of two elements of that kind
template<typename T>
Pair<T, T> make_pair_of(T a, T b) {
return {a, b};
}Socrates can simultaneously be regarded as an instance of the kind "person" and as a representative of the genera "mammal" and "biped," and it's important to understand that any entity belongs to exactly one kind, which sets the rules of its construction or existence, but may belong to many genera, each of which describes only one aspect of its properties — and exactly the same in programming: an object of one concrete type can implement many interfaces or concepts, each of which emphasizes only part of its behavior.
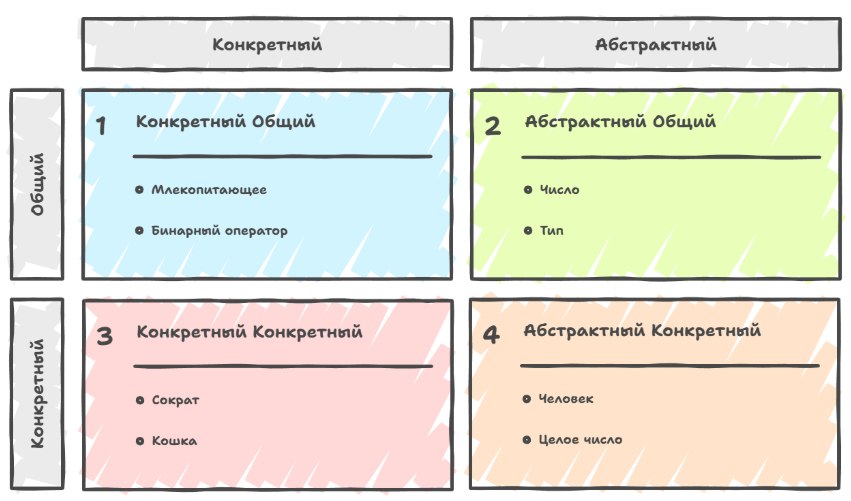
If we throw a bridge from this philosophical picture of the world to our world of compilers and C++, we can see that a type in the language plays the role of both a concrete kind and an abstract kind, depending on the level at which we look. From the standpoint of the program — a class
struct Person {
std::string name;
int age;
};sets the kind "person in our model," defining the set of attributes we chose as essential: name and age, while an object
Person p{"Socrat", 70};is a concrete entity, one person in our program, with its own attribute values at the current moment in time. From the standpoint of type theory in the compiler, "type" is closer to an abstract kind: the compiler works not with a concrete p but with the set of all possible values of the type Person, knows their size, structure, copy and destruction rules, and checks whether you correctly apply functions (rules, in our sense) to entities of the corresponding kinds, i.e. whether you're passing a std::string object into a function expecting a double, and vice versa.
Historically different compilers implemented this model differently at the level of internal representation, but on the whole the picture was always similar: in the compiler's internal data structures there are entities corresponding to abstract kinds and genera (these are nodes of the type tree), tables of information about classes, functions and templates, and there are entities corresponding to concrete entities (these are variables, objects, temporary values) that appear and disappear during program execution; and there are functions that, in the form of an intermediate representation (IR), turn into a set of rules for transforming some values into others.
In early compilers like cfront, many of these things were encoded in the textual C code produced at the translator's output, and the notions of kind and genus existed only in the author's head and in his design. As GCC, Clang and MSVC developed, ever more complex type systems and checks appeared that formalize these categories and allow, for example, at the level of LLVM IR, to speak of a type as a clearly defined "kind" of values for which equivalence, compatibility and the admissibility of certain operations can be checked.
┌───────────────────────────────────────────────────────────────────────┐
│ cfront (1983-1993) - Translation to C │
├───────────────────────────────────────────────────────────────────────┤
│ C++ code: cfront output (C code): │
│ ┌─────────────────────┐ ┌──────────────────────────┐ │
│ │ struct Person { │ │ struct Person { │ │
│ │ string name; │ → │ struct string name; │ │
│ │ int age; │ │ int age; │ │
│ │ │ │ }; │ │
│ │ void greet(); │ │ │ │
│ │ }; │ │ void Person_greet( │ │
│ │ │ │ struct Person* this │ │
│ │ Person p; │ │ ) { ... } │ │
│ │ p.greet(); │ │ │ │
│ └─────────────────────┘ │ struct Person p; │ │
│ │ Person_greet(&p); │ │
│ └──────────────────────────┘ │
│ Type information: │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ • Exists only in the programmer's head and in │ │
│ │ the code comments │ │
│ │ • The C compiler sees only struct Person │ │
│ │ • Methods → ordinary functions with this* │ │
│ │ • Type checking minimal (only at the C level) │ │
│ └──────────────────────────────────────────────────────────┘ │
└───────────────────────────────────────────────────────────────────────┘
┌───────────────────────────────────────────────────────────────────────┐
│ GCC/Clang (2000+) - Formal type system │
├───────────────────────────────────────────────────────────────────────┤
│ C++ code → AST → Type System → LLVM IR → Machine Code │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ C++ Source │ → │ Clang AST │ → │ LLVM IR │ │
│ ├──────────────┤ ├──────────────┤ ├──────────────┤ │
│ │ struct Person│ │ RecordDecl │ │ %Person = │ │
│ │ { │ │ name: │ │ type { │ │
│ │ string name│ │ FieldDecl │ │ %string, │ │
│ │ int age; │ │ Type: │ │ i32 │ │
│ │ }; │ │ string │ │ } │ │
│ │ │ │ age: │ │ │ │
│ │ Person p; │ │ FieldDecl │ │ %p = alloca │ │
│ │ p.greet(); │ │ Type: int│ │ %Person │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ Type information is stored in the compiler's data structures: │
│ ┌────────────────────────────────────────────────────────────┐ │
│ │ Type Database: │ │
│ │ ┌──────────────────────────────────────────────────────┐ │ │
│ │ │ Type: Person │ │ │
│ │ │ ├─ Size: 32 bytes │ │ │
│ │ │ ├─ Alignment: 8 │ │ │
│ │ │ ├─ Members: │ │ │
│ │ │ │ ├─ name: string at offset 0 │ │ │
│ │ │ │ └─ age: int32 at offset 24 │ │ │
│ │ │ ├─ Methods: │ │ │
│ │ │ │ └─ greet(): void │ │ │
│ │ │ ├─ Copy Constructor: auto-generated │ │ │
│ │ │ ├─ Destructor: calls ~string() │ │ │
│ │ │ └─ Move semantics: auto-generated │ │ │
│ │ └──────────────────────────────────────────────────────┘ │ │
│ │ │ │
│ │ Checks: │ │
│ │ • greet(Person) ← alice:Person OK │ │
│ │ • greet(Person) ← x:double ERROR │ │
│ │ • person.name ← "text" OK (string = char*) │ │
│ │ • person.age ← "text" ERROR (int ≠ char*) │ │
│ └────────────────────────────────────────────────────────────┘ │
└───────────────────────────────────────────────────────────────────────┘Values
When you run a program and look at memory from the processor's standpoint, there's no C++, no types, not even any numbers there — only long sequences of zeros and ones. The processor doesn't know what "the integer 42," "the real 3.14" or "the character 'A'" is: for it all of this is just different ways to interpret the same bits.
Until we have an interpretation of this data, we see just zeros and ones, as a sequence of bits, and everything else is the result of an agreement between the programmer, the compiler and the architecture about how to understand these bits.
A value type in this context can be thought of as a bridge between the abstract world of mathematical entities and the very concrete world of bit sequences, where on one side we have a kind of abstract things (like integers or rational numbers), and on the other side there's the set of all possible bit strings of the needed length, and the value type says which bit strings exactly we consider correct representations of entities of the given kind, and which not.
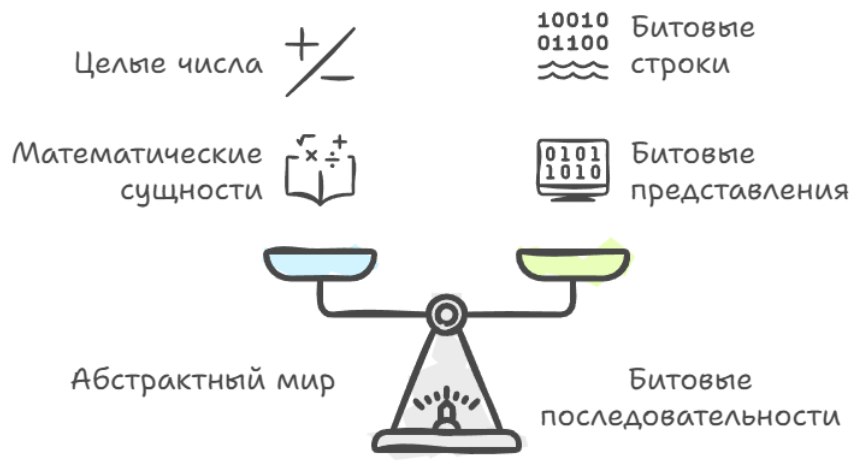
If we have a concrete entity, say the integer "minus five," then the set of bits with which we encode it in memory is called the representation of this entity, while the entity itself, i.e. the number as a mathematical object, is the interpretation of this data. When we say "value," we mean the data together with its interpretation: not just "32 bits 1111…," but "this is a 32-bit signed integer in two's complement with the value -5" or "this is a pair of 32-bit integers interpreted as the numerator and denominator of a rational number."
For example, an ordinary int on many platforms is 32 bits in two's complement, where the bit set 0x00000001 is interpreted as the number 1, and 0xFFFFFFFF as -1. A rational number can be represented as the concatenation of two such 32-bit integers, but it's important to understand that not every sequence of bits is a meaningful representation for an arbitrary value type. We can say that data is well-formed with respect to a type if it actually represents some abstract entity of that kind.
Any 32-bit sequence, if we agreed to interpret it as an integer in two's complement, will be well-formed: each bit set corresponds to some integer from the minimum to the maximum. But if we take the type "real number in the sense of a mathematical representation" and try to interpret an arbitrary IEEE 754 value, then, on encountering a NaN, we run into bits that by the IEEE 754 standard mean "Not a Number," and from the standpoint of pure mathematics they aren't a well-formed representation of a real number, although as an element of the type "machine float" they're perfectly legal.
That's exactly why in C++ the standard so distinguishes "the NaN bit set" and "a value of type double" as abstract entities, so the compiler and processor physically can store and pass NaN without experiencing any problems, but mathematical functions may be undefined for NaN.
// Each of these bit sets is meaningful as an int
uint32_t bits1 = 0x00000001u;
uint32_t bits2 = 0xFFFFFFFFu;
int32_t a, b;
std::memcpy(&a, &bits1, 4); // 1
std::memcpy(&b, &bits2, 4); // -1 (two's complement)Next arises the question: how fully does our value type cover the corresponding abstract kind. If a type represents only part of the possible entities, we call it "properly partial"; if every abstract entity of this kind can be expressed by a value of the given type, then "the type is complete."
A good example of a properly partial type is an ordinary int, which represents only a finite range of integers, although the set of mathematical integers is infinite; the type bool, on the contrary, is complete for the kind of logical values, because any abstract "true" and "false" map unambiguously to two possible values: true and false.
Historically compilers limited the range of int differently: on 16-bit systems these were ranges on the order of -32768…32767, on 32-bit and 64-bit ones much wider, but in all cases int remained a partial representation of the abstract kind "integer," and programmers had to remember about overflow and that far from every mathematical expression has a correct representation in this type.
y = nan
y + 1 = nan
y * 0 = nan
y == y = 0
sqrt(-1) = nanUniqueness of representation
A separate and very practically important topic is the uniqueness of representation, i.e. the question of whether each abstract entity corresponds to no more than one value of the given type. If we have a logical-value type implemented as a byte, where zero is false and any nonzero value is treated as true, then the representation isn't unique: 0x01, 0xFF, and 0x7F are all interpreted as true, and equality by meaning doesn't coincide with equality by bit content.
A type representing an integer as "sign bit plus magnitude" also has no unique representation of zero, because both "+0" and "-0" turn out to be different bit sets with the same interpretation.
Two's complement, on the contrary, has a unique representation: each integer in the allowed range is encoded by exactly one bit set, and zero has no "+0"/"-0" variant. Compiler and processor developers love such types with a unique representation, because the equality operation for them is trivially implemented as a bitwise comparison, and the optimizer can apply a mass of tricks based on the fact that replacing equal with equal preserves both the bits and the meaning.
But the opposite also happens: sometimes we deliberately choose a representation without uniqueness or even with ambiguity, when the same value can have more than one interpretation, i.e. from the bits you can't unambiguously reconstruct the abstract entity without additional context.
The example people like to cite is a calendar year encoded with two decimal digits: "42" can mean 1942, 2042 or some other year depending on the century; here the same sequence of data admits several interpretations, and the type is ambiguous in itself. In everyday work this shows up when you store dates without an explicit time zone — the bits take up less space, computations go faster, but equality by bits stops guaranteeing equality by meaning, and in the other direction, entities equal by meaning can have different representations.
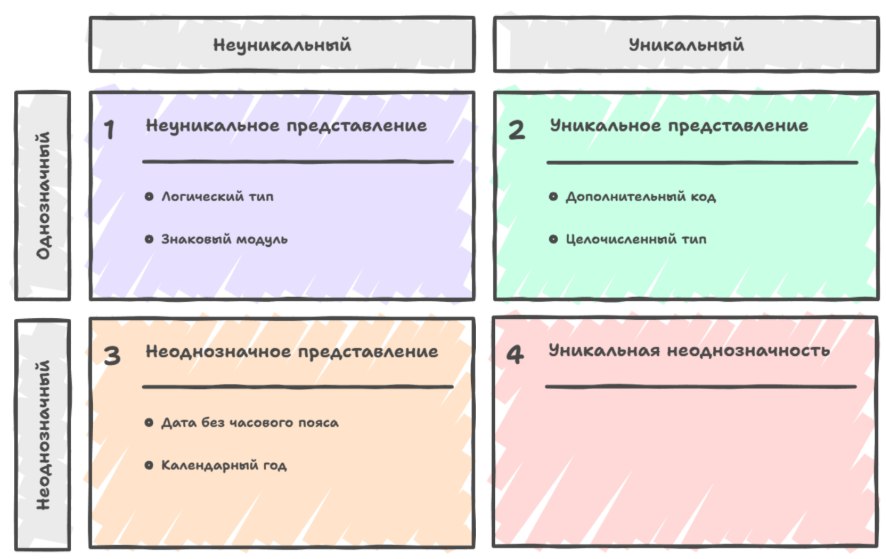
To carefully distinguish these situations, it's convenient to distinguish two kinds of equality: equality as a coincidence of interpretations, and "representational" equality as a literal coincidence of bit sequences. Two values of one type are equal if they describe one and the same abstract entity; they're representationally equal if the sequences of zeros and ones in their memory are identical.
If a type has a unique representation, then equality by meaning automatically entails equality by bits, because for each entity there's only one legal representation. If a type isn't ambiguous, i.e. each bit sequence corresponds to no more than one entity, then conversely, representational equality entails equality by meaning: identical bits will be the same entity.
That's exactly why for types like an ordinary int in two's complement or double (except for NaN), compilers calmly implement the == operator as either a direct comparison of bits or one or two machine comparison instructions, and the optimizer can replace the comparison with cheaper checks without fear of breaking the semantics.
But in real life we often encounter types where the uniqueness of representation is deliberately broken for the sake of the efficiency of value creation and transformation operations. Rational numbers stored as pairs of integer numerator and denominator without automatic reduction of the fraction would be a classic example: 1/2 and 2/4 represent the same abstract entity but have different representational forms, and to check their equality by meaning you need either to bring both fractions to irreducible form or to cross-multiply and compare the products, which is far more expensive than a simple comparison of two pairs of bit patterns.
// A complete type for a limited kind
// If the kind itself is finite - the type can be complete.
// Card suit: exactly 4 entities, exactly 4 enum values.
enum class Suit { Clubs, Diamonds, Hearts, Spades };
// Non-unique representation
struct Rational {
int64_t num; // numerator
int64_t den; // denominator (> 0)
bool naive_eq(...) // fast naive implementation
bool normalized_eq(...) // slow check with normalization
bool cross_eq(...) // slow check with cross-multiplication
};
auto a = Rational::make(1, 2); // 1/2
auto b = Rational::make(2, 4); // 2/4 - the same abstract entity
cout<<"1/2 naive_eq 2/4:"<<a.naive_eq(b)<<"\n"; // 0 -- wrong!
cout<<"1/2 normalized_eq 2/4:"<<a.normalized_eq(b)<<"\n"; // 1
cout<<"1/2 cross_eq 2/4:"<<a.cross_eq(b)<< "\n"; // 1Likewise, finite sets can be stored as unsorted lists of elements, where checking the equality of sets requires sorting and removing duplicates before you can compare element by element. In such situations the designer of the representation deliberately makes value creation and modification cheaper at the cost of making the equality check more expensive, if the latter is considered a rare operation. Historically you can find traces of such trade-offs in many standard libraries: from old implementations of std::set and std::multiset, where comparing values was cheap but insert operations more expensive, to experimental structures like hash sets, where, on the contrary, insertion and membership-check operations were optimized at the cost of a more complex equality and hashing scheme.
Sometimes implementing "true" behavioral equality is too expensive or even theoretically impossible: if you represent a computable function as some piece of code or a data structure describing an algorithm, then the notion "two functions are equal if they give the same result on all possible arguments" turns out to be uncomputable.
// Representation 1: Unsorted list
// Fast insert O(1), slow comparison O(n log n)
struct UnsortedSet {
std::vector<int> elements;
// Insert - O(1), just append to the end
void insert(int x) {
elements.push_back(x);
}
// Equality - O(n log n), need to sort
bool operator==(const UnsortedSet& other) const {
// Copy and sort for comparison
auto a = elements;
auto b = other.elements;
std::sort(a.begin(), a.end());
std::sort(b.begin(), b.end());
// Remove duplicates
a.erase(std::unique(a.begin(), a.end()), a.end());
b.erase(std::unique(b.begin(), b.end()), b.end());
return a == b;
}
};
// Representation 2: Sorted list (without duplicates)
// Slow insert O(n), fast comparison O(n)
struct SortedSet {
std::vector<int> elements; // Always sorted!
// Insert - O(n), need to maintain order
void insert(int x) {
auto it = std::lower_bound(elements.begin(), elements.end(), x);
if (it == elements.end() || *it != x) {
elements.insert(it, x); // O(n) due to shifting elements
}
}
// Equality - O(n), just compare element by element
bool operator==(const SortedSet& other) const {
return elements == other.elements; // Linear comparison
}
};In the general case it's impossible to algorithmically verify that two arbitrary algorithms behave identically over the whole domain, and so in practice you have to make do with a weaker notion of equality — comparison of representations, when two values are considered equal only if their bit images coincide, which corresponds to it being simply the same object in memory or an exact copy. To return to functions, we can put it this way — computers implement mathematical functions over abstract entities through concrete procedures over values, i.e. over bits plus their interpretation.
// ============================================
// FUNCTIONS: The impossibility of behavioral equality
// ============================================
// A function as an object (representation)
struct Function {
std::function<int(int)> impl;
std::string description;
int operator()(int x) const {
return impl(x);
}
// COMPARISON OF REPRESENTATIONS (weak equality)
// We can compare only the descriptions, not the behavior!
bool representation_equal(const Function& other) const {
return description == other.description;
}
// BEHAVIORAL EQUALITY (uncomputable!)
// To check f == g behaviorally, you need:
// ∀x: f(x) == g(x)
// But x ∈ ℤ₃₂ - that's 2^32 values
// And for functions with an infinite domain it's impossible at all
};Pure values
Although values live in memory and have addresses, a correctly implemented function should behave as if it's indifferent to the addresses at which the arguments lie, and care only about their content as values, and if we copy a value to another place, the result of applying the function to the old and the new copy should be the same.
When we say that a function is defined on a value type and is regular, we mean that it "respects" equality: if you replace an argument with any other value equal to it, the function's result doesn't change. Most familiar numeric functions, such as sin, cos, + or *, with careful implementation and rounding-mode setup, behave exactly this way: if two doubles really represent the same real number, then the result of addition or multiplication with any third arguments will be equal by meaning.
From the standpoint of type theory and the compiler's optimizer this is a very important remark, because such functions allow substitution, i.e. replacing expressions with ones equal to them without changing the program's behavior, while non-regular functions don't allow this, because inside them the choice of result may depend on exactly which bit pattern the value is written as.
double pos_zero = 0.0;
double neg_zero = -0.0;
cout<<"\n+0.0 == -0.0:"<<(pos_zero == neg_zero)<<"\n";
// 1 -- equal by ==
cout<<"signbit(+0.0):"<<std::signbit(pos_zero)<<"\n";
// 0
cout<<"signbit(-0.0):"<<std::signbit(neg_zero)<<"\n";
// 1 -- different result!
// signbit breaks regularity
// we replaced equal with equal, but the result changedIn the history of C++ compiler development this distinction has repeatedly surfaced in discussions about admissible optimizations: can you, for example, reorder floating-point computations or replace expressions with mathematically equivalent ones, given that the IEEE 754 format and the presence of NaN, infinities and rounding subtleties make many familiar identities, like the associativity of addition, false.
float a = 1e15, b = -1e15, c = 1.5;
float left = (a + b) + c; // (1e15 - 1e15) + 1.5 = 0 + 1.5 = 1.5
float right = a + (b + c); // 1e15 + (-1e15 + 1.5) -- precision loss
std::cout << "\n(a+b)+c = " << left << "\n"; // 1.5
std::cout << "a+(b+c) = " << right << "\n"; // may differ!
std::cout << "Equal: " << (left == right) << "\n";
// With -ffast-math the compiler could rearrange and get a different result
(a+b)+c = 1.5
a+(b+c) = 0
Equal: 0The standards committee and compiler developers sought a balance between the desire to aggressively optimize code and the need to preserve correctness for those functions and types that the programmer considers regular, and as a result modes like -ffast-math appeared, which deliberately weaken the guarantee of regularity for the sake of performance.
In the end, when designing the representation of any value type, two tasks inevitably go hand in hand: you need to decide which equality you want to have (bitwise or behavioral), with a unique representation or without, and which functions over this type you want to keep regular, so that the compiler and you yourself can safely apply the law "substitute equal for equal."
In C++ this shows up in the most varied places, from the choice of number and string formats to the design of wrapper classes and containers, and compilers, evolving from simple single-pass translators to modern multi-stage optimizers, increasingly rely on these properties of types to generate fast and at the same time correct code.
Objects
When in programming we say "object," it's very easy to jump straight to classes, methods and other OOP paraphernalia, although in fact everything begins much lower, at the level of memory itself and how bits live in it. Imagine memory as a large field of cells, where each cell has an address and content: the address and content (the data length) is a number, and to read a word at an address the processor performs a read operation, load, while to change the link between an address and content it does a write, store. In modern machines the role of such memory is played by regions in RAM, and at the level of disk storage the same model is implemented by blocks (logical storage regions) on an SSD or HDD, only with different latencies and rules of operation, but the principle is the same: there's an address, there's content, there are read and write operations.
Against this background an object can be understood as a contract between the programmer, the compiler and the machine as a way to represent a concrete entity from our domain world as a value living in memory. Every object has state, and this state is simply a value of some type. If an object describes a notional employee, then its state at the current moment is a "snapshot" of all the attributes we decided to store: name, salary, department identifier.
This state can change over time, and it's precisely in this that an object differs from a simple value, because a value in itself, as a mathematical representation, is immutable, while an object is capable of having different values at different moments in time. To store its state, an object owns a set of resources — these can be words of memory on the heap, records in a file, elements in a database; in the simplest case it's just several bytes in a row in dynamic memory.
// ============================================
// Variant 1: Array of Structures (AoS)
// Classic representation - the object's data lie next to each other
// ============================================
struct Complex_AoS {
double real;
double imag;
};
void example_aos() {
std::vector<Complex_AoS> numbers = {
{1.0, 2.0}, // first complex number
{3.0, 4.0}, // second
{5.0, 6.0} // third
};
// Access is natural - everything is adjacent
std::cout << "AoS: " << numbers[1].real << " + "
<< numbers[1].imag << "i\n";
}
Memory (bytes go one after another):
┌─────────────────┬─────────────────┬─────────────────┐
│ Complex[0] │ Complex[1] │ Complex[2] │
├────────┬────────┼────────┬────────┼────────┬────────┤
│ real: │ imag: │ real: │ imag: │ real: │ imag: │
│ 1.0 │ 2.0 │ 3.0 │ 4.0 │ 5.0 │ 6.0 │
└────────┴────────┴────────┴────────┴────────┴────────┘
0x1000 0x1010 0x1020 0x1030At the same time you have to understand that although we logically think of an object's value as a continuous sequence of zeros and ones, physically the resources in which these bits are stored aren't obliged to go in a row: the classic example is a complex number as a pair of doubles, the real and imaginary parts, which in memory may lie next to each other, or may be spread across different structures or arrays, and still the interpretation will gather them into one logical whole. If we manually switched from an array of structures {re, im}[] to two separate arrays re[] and im[], then the fields of one logical object physically live in different regions of memory, being one object only by the convention of interpretation.
// ============================================
// Variant 2: Structure of Arrays (SoA)
// The data of one logical object is spread across memory
// ============================================
struct ComplexArray_SoA {
std::vector<double> real; // all real parts in a row
std::vector<double> imag; // all imaginary parts in a row
size_t size() const { return real.size(); }
// The logical "object" with index i is the pair (real[i], imag[i])
// but physically they live in different arrays
struct ComplexRef {
double& re;
double& im;
ComplexRef(double& r, double& i) : re(r), im(i) {}
// Behaves like an object, but the data aren't adjacent!
void print() const {
std::cout << re << " + " << im << "i\n";
}
};
ComplexRef operator[](size_t i) {
return ComplexRef(real[i], imag[i]);
}
};
Memory (arrays in different places):
Array real[] (all real parts):
┌────────┬────────┬────────┐
│ 1.0 │ 3.0 │ 5.0 │ ← real[0], real[1], real[2]
└────────┴────────┴────────┘
0x2000 0x2008 0x2010
Array imag[] (all imaginary parts):
┌────────┬────────┬────────┐
│ 2.0 │ 4.0 │ 6.0 │ ← imag[0], imag[1], imag[2]
└────────┴────────┴────────┘
0x3000 0x3008 0x3010
Logical object Complex[1] = {real[1], imag[1]}
= {3.0 from 0x2008, 4.0 from 0x3008}In distributed systems the resources of one logical object can end up in different kinds of memory altogether, for example part in RAM, part on disk or in remote storage, but usually when describing an object we imply one process, one address space, a unique starting address and fixed offsets to all of its parts.
The object type in such a picture of the world is a template of how we store and change values in memory, and we can say that for each object type there's a corresponding value type that describes all the admissible states of objects of this type.
If we agreed that our object will be a 32-bit signed integer in two's complement with little-endian byte order and alignment on a 4-byte boundary, then we've thereby specified a concrete object type: the compiler knows its size in bytes, where it can be located in memory, which processor instructions to use for loading and writing, while the value type for this object will be the set of all integers in the allowed range.
Any concrete "int" object in the program belongs to this object type: its state is some concrete value, while its physical realization is a set of bytes in memory that the compiler accesses by a known offset from the starting address. An important point that's useful to realize in your first attempts at writing code is that values and objects are complementary but fundamentally different in their roles.
Values as mathematical entities are immutable and don't depend on how we encoded them in memory; you can write the number 42 on paper, convey it orally, send it over the network as text or as a binary format, and the value itself won't change from this.
Objects, on the contrary, are tied to a concrete machine and implementation: they have an address, a set of bytes, a mechanics of change, and they can transition from one state to another during the program's life.
But nevertheless the state of any object at a concrete moment can always be described by a value: you can take a std::string object, look at its value as a sequence of characters, write it on paper or serialize it to JSON — and this will be a "snapshot" of the object's state.
When we discuss the equality of objects, we most often want to talk precisely about the equality of their states as values, abstracting away from the fact that one std::string stores its data in one region of memory and another in a different one. Such a view is important in purely functional languages, where there are no mutable objects but only values and functions, but in C++ too it lets us separate "what" from "how" and not tie everything to concrete addresses.
Why do we use objects at all?
First, objects very naturally model mutable concrete entities of the real world: a record about an employee in a database, a character object in a game, the state of a window in a GUI would be constructs that change as the program runs, and objects with mutable state that describes them close to reality.
Second, even when we're interested in purely abstract values, like the square root of a number or the solution of a system of linear equations, we almost always implement these functions through algorithms that use mutable memory: iterative methods, accumulation of intermediate sums and so on, and objects in this sense serve as a tool for implementing functions over values.
Third, if we look very fundamentally, the universal model of computation by Turing implies a machine with memory, and a real computer is exactly such a machine, so any practical implementations of computation still come down to manipulating objects in memory, even if at the language level this is disguised as "pure functions."
Part of the properties for value types carry over to object types too. If a value is well-formed and its binary representation is admissible for the chosen type, then an object with such a state is correct too; if the value type is properly partial, representing only part of the possible abstract entities (like int with respect to all integers), then the object type implementing this int will be partial too; if the value type has a unique representation, like two's complement for integers, then for objects of this type equality by meaning can be implemented through comparison of bytes, which is historically important for optimization, giving compilers the ability to reduce comparison of POD-type objects to a simple memcmp, if they know that the representation is unique and there are no "holes" with uninitialized bits, or go further and replace memcmp with a direct comparison of registers or vector instructions — but you should remember that a pure transfer of operator== → memcmp for structs with possible padding leads to potential bugs.
I'll wrap up here, and about identity, procedures, the computational basis and regularity I'll tell in the next part...
← All books