

C и C++ не имеют встроенной сборки мусора, поэтому разработчик сам решает, как и когда выделять и освобождать память. Мы, конечно, можем покивать в сторону STL, сокрытия аллокаций в контейнерах, но от этого они никуда не денутся. Просто если раньше приходилось думать про выделенный кусок памяти, понимать, как он скажется на времени фрейма, помнить, что его надо удалить (а может, не надо и стоит оставить на следующий фрейм), то теперь всё заворачивается в сахарные контейнеры и разработку в стиле STL-blin-vse-sterpit. STL-то может и стерпит, и даже как-то будет ворочаться, однако не стоит полагаться исключительно на системный аллокатор, бездумно вызывая new или malloc для каждого запроса памяти. Вы ведь понимаете, что std::vector посреди цикла — это плохая идея?
Кроме того, такая практика приводит к ожидаемым проблемам с производительностью даже в обычных приложениях, чего уж говорить про высоконагруженные системы или игры, которые претендуют на что-то быстрее 20 фреймов в секунду.
Пытаться оптимизировать код, который использует системные аллокаторы, — всё равно что сгребать листья в кучу ветреным днём: куча, конечно, сгребается, но постоянно приходится махать грабельками, чтобы она оставалась на одном месте. Даже если выделения памяти происходят последовательно, друг за другом, вот прям без всяких перерывов, нет гарантии, что эти участки будут расположены хотя бы близко друг к другу. В результате при обработке таких данных процессору приходится прыгать по разным участкам памяти, теряя такты просто на поиск данных вместо того, чтобы работать с ними.
Я отнюдь не призываю вас встать на путь ручного управления памятью, ибо он будет усеян ловушками, граблями и чреват утечками. Но разработчик в итоге оказывается перед выбором: либо довериться системному аллокатору и столкнуться с проблемами вроде размазанного перфа, когда вроде и код написан правильно, модно и молодёжно, но отчего-то работает небыстро, либо взять всё в свои руки, создавая собственные механизмы выделения и освобождения ресурсов.
Ребята из HFT, Database, Automotive и Embedded-систем наверняка могут рассказать немало интересных историй про оптимизацию new/delete. Давайте я расскажу немного про разные аллокаторы в играх?
Это часть серии «Game++»:
- Game++. String interning
- Game++. Cooking vectors
- Game++. Dancing with allocators <=== Вы тут
- Game++. Juggling STL algorithms
- Game++. run, thread, run...
- Game++. Building arcs
- Game++. Unpacking containers
- Game++. Heap? Less
- Game++. Work hard
- Game++. Patching patterns
- Game++. while (!game(over))
- Game++. Bonus. Performance traps
Многим людям сложно разобраться с парадигмами управления памятью. Языки программирования (даже мои любимые плюсы), фреймворки, движки и т. д. всё навязчивее пытаются скрыть этот процесс за красивым фасадом и яркими названиями, вроде сборки мусора (GC), подсчёта ссылок (ARC, RC), RAII (Resource Acquisition Is Initialization) или семантики владения.
(Небольшой словарик, если вам какие-то слова показались непонятными.)
Глоссарий по управлению памятью
Ручное управление памятью (Manual management). Вместо автоматического сборщика мусора можно явно выделять и освобождать память для объектов. Требует тщательного отслеживания операций выделения и освобождения памяти и до сих пор является источником ошибок, если управление выполняется некорректно. Игры до 2000-х.
Подсчёт ссылок (RC). Отслеживаем количество ссылок на объект. Каждый раз, когда создаётся или уничтожается ссылка, счётчик обновляется. Если счётчик ссылок достигает нуля, объект освобождается. Подсчёт ссылок вызывает дополнительные накладные расходы, а также страдает от проблемы циклических ссылок, когда объекты ссылаются друг на друга, и их счётчики ссылок никогда не достигают нуля. Игры с конца 90-х.
Автоматический подсчёт ссылок (ARC). Похож на подсчёт ссылок, но стремится решить некоторые его проблемы с помощью дополнительных методов вроде операций удержания (retain) и освобождения (release) для управления счётчиками ссылок. Позволяет устранить некоторые проблемы с циклическими ссылками и уменьшить накладные расходы подсчёта ссылок. Frostbite/Unity/CryEngine.
Типы владения. Используется статический анализ для управления памятью. Система типов владения отслеживает и обеспечивает соблюдение отношений владения между объектами, гарантируя, что память освобождается, когда она больше не нужна. Типы владения позволяют устранить некоторые ошибки, связанные с памятью, и предоставляют гарантии на этапе компиляции, но сильно усложняют разработку и требуют дополнительных аннотаций. В основном Rust (Amethyst/Bevy/Fyrox/Godot).
Внутренняя фрагментация. Объём памяти, который был выделен, но не используется внутри блока. Возникает, когда аллокатор выделяет больше памяти, чем требуется. Например, аллокатор не умеет выделять блоки меньше 8 байт или не кратные этому размеру, тогда попытка выделить 13 байт под объект приведёт к 2 × 8 = 16 − 13 = 3 байтам потери на каждый объект.
Внешняя фрагментация. Объём памяти, который не может быть использован для аллокации запрошенного объёма, даже если он суммарно доступен. Возникает из-за «дырок». У аллокатора есть 1000 байт, игра запрашивает блоки 300, 500 и 200 байт, а затем освобождает первый и последний. В наличии два свободных блока: 300 и 200 байт. Но при запросе всего, что выше 300 байт, аллокатор не сможет ничего выделить, хотя в общем доступно 500 байт.
Блок, Header, Lifetime. Блок: фрагмент выделенной памяти, в зависимости от контекста может включать или не включать заголовок (Header) и хвост (Tail). Lifetime: общее количество операций (косвенно время) между операциями allocate/deallocate для конкретного блока. Header/Tail: внутренняя структура данных, содержащая данные о блоке, времени создания, размере, хедерчеке и т. д. Добавляет накладные расходы при управлении памятью.
Garbage collector. Аллокатор, который автоматически предоставляет память по мере необходимости без необходимости явно освобождать её после использования. Вместо этого сборщик мусора периодически проверяет, какие объекты всё ещё используются приложением (то есть «живы»). Подробно описаны в книге Джонса и Линса (1987).
Однако абстрагирование от управления памятью обходится тем дороже, чем больше абстракций мы туда навертели. Даже среди моих коллег я слышу объяснение дуализма памяти «стек vs куча» как что-то вроде: стек автоматически расширяется при вызове процедуры, а куча является неким неограниченным механизмом для получения памяти, которая должна сохраниться на протяжении жизни игры.
Но такой подход к памяти неверен и формирует вредную, ошибочную модель, в которой стек воспринимается как «некая» особая форма памяти и создаёт иллюзию, будто два типа памяти работают принципиально по-разному. Однако на физическом уровне это всё те же области одного адресного пространства.
Самый простой и наглядный пример, как по мне, был у моего преподавателя по теории ОС. В аудитории стояли книжный шкаф и книжная полка с книгами разного размера. На одной из лекций по организации памяти он вызвал студента и попросил его добавлять и убирать книги в случайном порядке, при этом оставшиеся двигать было нельзя.
Со временем между книгами образовались пустоты, куда новые книги уже не помещались. И хотя изначально все книги стояли на полке, через минут пять часть из них осталась лежать на столе. Эксперимент заканчивался эффектным сдвиганием книг на полке и водворением остальных на место.
То же самое происходит и с памятью: даже если общий объём свободной памяти достаточен, она может быть настолько фрагментирована, что аллокатор не сможет найти непрерывный блок нужного размера. Вот только схлопнуть память не так просто, а иногда и вовсе невозможно.
Ещё одним неприятным эффектом от динамических аллокаций, хотя и не таким заметным, но от этого не менее вредным, является фрагментация памяти — проблема, которая возникает, когда системному аллокатору приходится тратить время на поиск подходящего блока среди миллионов других. Это происходит из-за того, что мелкие аллокации (и освобождения) памяти приводят к дыркам, и она начинает выглядеть словно пазл, где потерялись части.
Этот процесс не только отбирает память у самой игры, но и в прямом смысле замедляет работу программы в соотношении примерно 1 к 1. То есть чем больше фрагментирована память, тем медленнее работает и сама игра. Это справедливо для большинства стандартных аллокаторов.
В среднем для качественно спроектированных игр рост фрагментации памяти не должен превышать 2% в час. Существуют отдельные нагрузочные и фаззинг-тесты, которые позволяют определить, как «портится» куча со временем.
Чтобы избежать этих эффектов, приходится искать альтернативные подходы для снижения фрагментации и сохранения производительности. Аллокаторов придумали много видов, каждый из них хорош в определённых алгоритмах или условиях. И нет, идеального аллокатора не существует.
Ссылки могут иногда вести на смежные темы, которые не всегда относятся точно к нужному аллокатору, но чтиво точно будет интересное.
Linear allocator

Это один из самых простых и эффективных механизмов управления памятью, который часто используется в ситуациях, где требуется высокая производительность и минимальные накладные расходы. Его работа напоминает движение по прямой линии: память выделяется последовательно, без возможности освобождения отдельных блоков до тех пор, пока не будет освобождена вся выделенная область целиком.
struct LinearAllocator {
void* base_pointer;
size_t size;
size_t offset;
void* allocate(size_t alloc_size) {
if (offset + alloc_size > size) return nullptr;
void* ptr = static_cast<char*>(base_pointer) + offset;
offset += alloc_size;
return ptr;
}
void reset() {
offset = 0;
}
};В игровых движках линейный аллокатор часто используется для:
- Выделения памяти под временные данные, например для рендеринга кадра, потому что после этого они уже становятся неактуальны. В конце кадра вся память освобождается, и аллокатор сбрасывается.
- В процессе обсчёта физики (например, для расчёта столкновений или движения объектов) для временных данных. Так как такие объекты обычно краткоживущие, с временем жизни не дольше нескольких фреймов, то хранят N последних до достижения лимита, потом копируют их в начало и продолжают аллокацию нового хвоста.
- Системы частиц (дым, огонь, взрывы) тоже часто используют линейный аллокатор, такие данные живут только в течение одного-двух фреймов.
- При расчёте анимации персонажей создаются временные данные, такие как матрицы трансформации костей или промежуточные состояния анимации.
- В процессе обработки звука (например, для эффектов реверберации, объёмных или звуковых ям) создаются временные буферы, которые после отправки в драйвер становятся не нужны.
[ Начало памяти ] [ Конец памяти ]
|----------------------------------|
^ ^
start_ptr end_ptr
▼ После выделения памяти ▼
|-----A-----B----C-------| |
^ ^ ^ ^
start_ptr current_ptr end_ptrИнтересное по теме: molecular-matters: a linear allocator, Kashio/A5, bitsquid: custom memory allocation.
Step-back allocator

Разновидность linear allocator с возможностью удаления последнего выделенного блока, если он совпал с тем, что был выделен последним. Широко применяется в игровых движках для всевозможных текстовых парсеров (JSON, XML, KV) и генераторов, где важна высокая производительность и проявляется паттерн краткосрочных аллокаций стекового типа.
class StepBackAllocator {
public:
StepBackAllocator(size_t size)
: buffer(new char[size]), capacity(size), offset(0) {}
~StepBackAllocator() {
delete[] buffer;
}
void* allocate(size_t size) {
if (offset + size > capacity) {
return nullptr;
}
void* ptr = buffer + offset;
history.push_back(ptr); // Сохраняем текущую позицию
offset += size;
return ptr;
}
void deallocate(void* ptr) {
if (history.empty()) {
assert("No allocations to deallocate.");
}
if (history.back() == ptr) {
// Откатываем указатель вершины на предыдущую позицию
history.pop_back();
}
}
void reset() {
offset = 0; // Сбрасываем указатель в начало
history.clear();
}
private:
char* buffer; // Буфер памяти
size_t capacity; // Общая ёмкость буфера
size_t offset; // Текущая позиция в буфере
std::vector<void*> history; // История выделений
};Часто используется для:
- Текстовые парсеры (JSON, XML, KV): когда надо парсить текстовые данные, такие как конфигурационные файлы, описания уровней, метаданные. Парсеры работают с краткоживущими временными объектами, по модели «прочитал — удалил», которые хорошо откатываются после обработки.
- Процедурная генерация: в играх с процедурной генерацией, таких как рогалики, объекты могут быть созданы и уничтожены на лету. Step-back-аллокатор позволяет не тратить время на освобождение памяти для таких объектов при генерации мира.
Минусы существенные — надо помнить, что это «ненормальная» память. Основное ограничение в том, что освобождение памяти возможно только по принципу LIFO (Last In, First Out) либо сразу всей области. Это может быть неудобно, если требуется освобождать память в произвольном порядке.
При работе с таким аллокатором важно понимать, что память для долгосрочных объектов должна быть зафиксирована. Нельзя хранить указатель на адрес из такого аллокатора, потому что в какой-то момент он будет сброшен.
[ Начало памяти ] [ Конец памяти ]
|----------------------------------|
^ ^
start_ptr end_ptr
current_ptr = start_ptr
▼ После нескольких аллокаций ▼
|-----A-----B----C-----------------|
^ ^ ^ ^
start_ptr │ current_ptr end_ptr
└─ (marker для B)
▼ После pop() последнего блока (C) ▼
|-----A-----B|---------------------|
^ ^ ^
start_ptr current_ptr end_ptrFrame allocator

Это специализированный вид linear-аллокатора, который используется для управления памятью в циклических или временных алгоритмах, где данные часто выделяются и освобождаются в рамках определённого времени (например, кадра, нескольких кадров, одного хода, одной секунды и т. д.). Они особенно хороши там, где требуется высокая производительность и минимальные накладные расходы на управление памятью, однако их недостатком является узкая область применения.
Принцип работы сводится к тому, что в течение одной итерации (например, одного хода в пошаговой стратегии) память выделяется последовательно, как в линейном аллокаторе. Указатель перемещается вперёд при каждом запросе на выделение. В конце кадра (итерации) вся выделенная память освобождается сразу, а указатель сбрасывается на начало блока памяти. Реализация ничем не будет отличаться от linear-аллокатора, просто добавим возможность отслеживать, когда была произведена очистка.
class FrameAllocator {
void* base_pointer;
size_t size;
size_t offset;
uint32_t frame;
void* allocate(size_t alloc_size, uint32_t f) {
if (offset + alloc_size > size) return nullptr;
frame = f;
void* ptr = static_cast<char*>(base_pointer) + offset;
offset += alloc_size;
return ptr;
}
void reset() {
offset = 0;
}
};Кадр 1:
[ A | B | C | ... свободная память ... ]
^ ^
current_ptr end_ptr
▼ После завершения кадра 1 ▼
Кадр 2:
[ D | E | ... свободная память ... ]
^ ^
current_ptr end_ptr
▼ После завершения кадра 2 ▼
Кадр 3:
[ F | G | H | ... свободная память ... ]
^ ^
current_ptr end_ptrИнтересное по теме: nfrechette: stack frame allocators, Srekel/sralloc.
Double-Frame allocator (Double-Buffered)

Дальнейшее развитие идеи фрейм-аллокатора. Выделяются две области памяти (под фреймы), которые используются поочерёдно: в текущем кадре данные записываются в одну область, а в следующем кадре эта область очищается и переиспользуется, пока данные записываются во вторую область.
Хорош для данных, живущих в пределах одного кадра. Сохраняет все качества linear-аллокатора, нет затрат на частое выделение и освобождение памяти, и достаточно лёгок в реализации и использовании. Используется для эффектов и интерполяции между кадрами (например, сглаживание движений камеры или объектов, карты движений и шахматного рендеринга).
class DoubleFrameAllocator {
FrameAllocator allocators[2];
uint32_t frame = 0;
public:
void* allocate(size_t size) {
return allocators[frame % 2].allocate(size);
}
void swapBuffers() {
allocators[currentAllocator].reset();
++frame;
}
};Из минусов: память можно использовать только в течение двух кадров, данные с прошлого фрейма остаются в памяти, надо в два раза больше памяти, и половина её всегда неактуальна.
Кадр N:
Пул 1 (активный): [ A | B | C | ... свободно ... ]
Пул 2 (неактивный): [ D | E | ... свободно ... ] ← Данные с кадра N-1
▼ После завершения кадра N ▼
Кадр N+1:
Пул 1 (неактивный): [ A | B | C | ... ] ← Данные сохраняются для кадра N+1
Пул 2 (активный): [ F | G | ... свободно ... ]
▼ После завершения кадра N+1 ▼
Кадр N+2:
Пул 1 (активный): [ H | ... свободно ... ] ← Пул 1 сброшен, данные кадра N удалены
Пул 2 (неактивный): [ F | G | ... ] ← Данные сохраняются для кадра N+2N-Frame allocator (Multi-Frame)

Расширяет концепцию фрейм-аллокатора, создавая несколько (N) областей памяти под фреймы, которые используются циклически. Каждый фрейм использует одну из этих областей для размещения своих данных, пока остальные остаются доступными для чтения. Этот подход используется, если данные из предыдущих кадров нужны в течение нескольких фреймов, например, для рендеринга с задержкой или эффектов Motion Blur, Temporary AA.
Плюсы те же — высокая скорость выделения памяти. Минусов становится больше: нужно больше памяти под каждую из N областей. Увеличение количества фреймов требует более сложного механизма синхронизации переключения, но в принципе остаётся несложным для понимания и реализации.
Основной недостаток — это перерасход памяти. Зачастую неудобно хранить какие-то отдельные участки фрейма, и приходится хранить его целиком, что для 4K-разрешений требует хранения существенных объёмов. Хотя кто сейчас считает эти мегабайты, когда стали использовать 5K PNG в качестве фонов?
template<int N>
class NFrameAllocator {
FrameAllocator allocators[N];
uint32_t frame = 0;
public:
void* allocate(size_t size) {
return allocators[frame % N].allocate(size);
}
void nextFrame() {
allocators[currentAllocator].reset();
++frame;
}
};Интересное по теме: gamedev.net: introduction to allocators and arenas.
Stack allocator

Ещё один «золотой» аллокатор, в смысле простой и эффективный, который широко используется в разных системах, где важны скорость, предсказуемость и минимальные накладные расходы. Он основан на принципе стека, как видно из названия: память выделяется и освобождается в строгом порядке LIFO (Last In, First Out), то есть последний выделенный блок памяти должен быть освобождён первым.
При инициализации стековый аллокатор получает большой непрерывный блок памяти, который будет использоваться для внутренней работы. Внутри аллокатора хранится указатель (или «вершина стека»), который указывает на начало свободной области памяти. Когда программа запрашивает память, аллокатор перемещает указатель вперёд на размер запрашиваемого блока и возвращает адрес начала этого блока. Память освобождается в порядке, обратном выделению.
Чтобы освободить блок, указатель перемещается назад на размер этого блока. Переиспользовать произвольный участок нельзя (условно нельзя), но можно сбросить весь стек сразу.
class StackAllocator {
public:
StackAllocator(size_t size) {
buffer_ = std::malloc(size);
capacity_ = size;
current_ = buffer_;
}
~StackAllocator() {
std::free(buffer_);
}
void* allocate(size_t size) {
const size_t required_space = sizeof(Header) + size;
if (current_ + required_space > buffer_ + capacity_) {
return nullptr;
}
Header* header = (Header*)current_;
header->size = size;
current_ += sizeof(Header);
void* user_ptr = current_;
current_ += size;
return user_ptr;
}
void deallocate(void* ptr) {
if (!ptr) {
return;
}
char* user_ptr = static_cast<char*>(ptr);
Header* header = (Header*)(user_ptr - sizeof(Header));
if (user_ptr + header->size != current_) {
assert("free inproperly");
}
current_ = header;
}
private:
struct Header {
size_t size;
};
void* buffer_;
size_t capacity_;
void* current_;
};Хорошо подходит для рекурсивных алгоритмов, а-ля поиска пути (pathfinding), обработки графов, иерархий объектов, а также когда порядок и зависимости объектов памяти чётко определены.
В качестве примера можно привести поиск пути (A*). В классической реализации для каждого шага создаются временные ноды, которые после завершения вычислений могут быть освобождены в порядке, обратном созданию (между нодами A* всегда есть связь). Другим примером будет система событий, когда они должны быть обработаны в порядке прихода (или обратном). Или локальные стеки алгоритмов, например, при загрузке уровней.
[ Начало памяти ] [ Конец памяти ]
|-------------------------------|
^ ^
start_ptr end_ptr
new A,B
|A|B|----------------------------|
^ ^
current_ptr end_ptr
delete B
|A|------------------------------|
^ ^
current_ptr end_ptr
delete A
|--------------------------------|
^ ^
current_ptr end_ptr
|---- закончили упражнение ------|Преимущества: быстрое выделение памяти, минимальная фрагментация, отличная локальность данных.
Интересное по теме: mtrebi/memory-allocators, molecular-matters: a stack-like LIFO allocator.
Double-stack allocator

Одним из самых полезных расширений предыдущего аллокатора является то, что обычно называется двусторонним стековым аллокатором. Он позволяет выделять память с обоих концов стека, что даёт возможность размещать разные типы аллокаций на разных стеках.
Лучшим применением для такого аллокатора снова будет загрузка уровней и моделей. И модели, и уровни обычно содержат набор данных, которые хорошо ложатся в последовательную память. Загрузка уровней сама по себе — очень затратная операция, потому что легко приводит к значительной фрагментации из-за большого числа временных объектов.
class DoubleStackAllocator {
public:
DoubleEndedStackAllocator(size_t size)
: totalSize(size), start(nullptr), end(nullptr), current(nullptr), reverse(nullptr) {
start = malloc(size);
end = (char*)start + size;
current = start;
reverse = end;
}
~DoubleEndedStackAllocator() {
free(start);
}
void* allocateFromStart(size_t size) {
// Проверка на переполнение стека с начала
if ((char*)current + size <= (char*)reverse) {
void* result = current;
current = (char*)current + size;
return result;
}
return nullptr; // Нет достаточно памяти
}
void* allocateFromEnd(size_t size) {
// Проверка на переполнение стека с конца
if ((char*)reverse - size >= (char*)current) {
reverse = (char*)reverse - size;
return reverse;
}
return nullptr; // Нет достаточно памяти
}
void reset() {
current = start;
reverse = end;
}
private:
size_t totalSize;
void* start;
void* end;
void* current;
void* reverse;
};Представьте случай, когда во время загрузки модели нам понадобился временный объект A, данные которого используются в другом объекте B. Нельзя освободить A, потому что нужно генерировать данные для B, и нельзя освободить A после B, потому что принцип LIFO не позволяет это сделать. Типичный пример такой фрагментации — читаем конфиг модели из OWN/YAML/JSON-файла и создаём ресурсы на основе этого конфига.
Чтобы избежать временных аллокаций из конфига, будем их размещать с одного края стека, а основные объекты — с другого. Пока два хэда не встретятся в процессе загрузки, мы будем иметь столько же памяти, сколько и при использовании простого стекового аллокатора, но память основных объектов не будет подырявлена мелкими объектами конфига.
[ Long ] уровень [ Short ] конфиг
|-------------------------------|
^ ^
lg_ptr sh_ptr
new(l) A, new(s) B
|A|---------------------------|B|
^ ^
lg_ptr sh_ptr
new(s) C
|A|-------------------------|C|B|
^ ^
lg_ptr sh_ptr
new(l) D (delete C, B) -- закончили загрузку, убрали аллокации для конфига
|A|D|---------------------------|
^ ^
lg_ptr sh_ptr
для обычного аллокатора
|A|B|С|D|-----------------------|
^ ^
ptr end_ptrPointed Double-Stack Allocator

Есть небольшая вариация аллокатора с двумя стеками, когда они растут из некоторой точки общего буфера. В этом случае память выделяется не с двух концов, а с расширением в обе стороны. Опять же, такой подход позволяет эффективно управлять памятью для различных типов объектов, которые могут иметь разные требования к жизненному циклу. Например, объекты, которые должны быть активны на протяжении всей работы уровня, могут выделяться с одной стороны, а временные объекты — с другой.
Основное преимущество такого аллокатора — это возможность динамически управлять различными типами выделений, одновременно минимизируя вероятность переполнения или конфликтов между ними. Неявное преимущество: блок памяти одного из аллокаторов, который растёт «вперёд», можно попробовать реаллоцировать, если есть свободный объём, не перемещая его физически.
Недостатком такого подхода является необходимость предварительного профилирования расхода памяти и настройки, и в большинстве случаев его можно заменить на пару обычных stack-аллокаторов.
конфиг [Short ][ Long ] уровень
|--------------|----------------------------|
^ ^
sh_ptr lg_ptr
new(l) A, new(s) B
|------------|B|AAAAAAAAAAAAAAAAAAA|--------|
^ ^
sh_ptr lgh_ptr
new(s) C, new(l) D
|----------|C|B|AAAAAAAAAAAAAAAAAAA|--------|
^ ^
sh_ptr lgh_ptr
не хватает для D -> realloc(long)
|----------|C|B|AAAAAAAAAAAAAAAAAAA|DDDDDDDDDDDDDDDDDDD|-----|
^ ^
sh_ptr lgh_ptr
delete C, delete B
|--------------|AAAAAAAAAAAAAAAAAAA|DDDDDDDDDDDDDDDDDDD|-----|
^ ^
sh_ptr lgh_ptrPool allocator

Посидели умные люди, посмотрели на linear-аллокатор и подумали: а что если сделать аллокатор сразу под конкретный объект? Есть, например, у нас в игровом городе 32 NPC, мы создаём их, когда игрок подходит к городу. Зачем нам использовать аллокаторы общего назначения для группы объектов, увеличивая энтропию вселенной?
Примерно так появились на свет пул-аллокаторы, которые выделяют память блоками одинакового размера, что полностью убирает фрагментацию для конкретной группы объектов и (в теории) должно ускорять выделение/освобождение памяти. В идеальном случае это должно вообще убрать затраты на пересоздание объектов, потому что появляется возможность переиспользовать уже существующие.
При инициализации такой аллокатор резервирует большой кусок памяти за один вызов и делит его на равные части — блоки. При запросе памяти он возвращает первый свободный блок (O(1)), а при освобождении — добавляет блок обратно в список.
class PoolAllocator {
struct Block {
Block* next;
};
void* memoryPool; // Выделенная память
Block* freeList; // Список свободных блоков
size_t blockSize; // Размер одного блока
size_t totalBlocks; // Общее количество блоков
public:
PoolAllocator(size_t objectSize, size_t numObjects) {
// Делаем размер блока под выравнивание и размер указателя
blockSize = (objectSize < sizeof(Block)) ? sizeof(Block) : objectSize;
totalBlocks = numObjects;
// Большой блок
memoryPool = std::malloc(blockSize * totalBlocks);
// Маленькие блоки
freeList = static_cast<Block*>(memoryPool);
Block* current = freeList;
for (size_t i = 0; i < totalBlocks - 1; ++i) {
current->next = reinterpret_cast<Block*>(reinterpret_cast<char*>(current) + blockSize);
current = current->next;
}
current->next = nullptr;
}
~PoolAllocator() {
std::free(memoryPool);
}
void* allocate() {
if (!freeList) return nullptr; // Пул пуст
Block* allocatedBlock = freeList;
freeList = freeList->next;
return allocatedBlock;
}
void deallocate(void* ptr) {
if (!ptr) return;
Block* freedBlock = static_cast<Block*>(ptr);
freedBlock->next = freeList;
freeList = freedBlock;
}
};Достоинства: быстрое выделение/освобождение, минимальная фрагментация, предсказуемое время выполнения — полезно для объектов, которые массово и часто создаются и уничтожаются, например: пули, эффекты, частицы, игровые сущности.
К недостаткам можно отнести фиксированный размер блоков и относительную неуниверсальность пулов: если объекты разного размера, нужны разные пулы. Ну и приходится заниматься предварительной настройкой пулов, чтобы уменьшить избыточность, когда блоки не полностью используются.
Интересное по теме: endurodave/Allocator, dmitrysoshnikov: writing a pool allocator, gingerbill: pool allocator.
Free List Allocator

Посмотрели другие мудрые люди на пул-аллокатор и подумали, что можно сделать пул, который разделяет предоставленную память на блоки одинакового размера и отслеживает, какие из них свободны. Пул-аллокатор хорош тем, что позволяет освобождать память в произвольном порядке за постоянное время O(1), при этом создавая минимальную фрагментацию. Но вот что неудобно, так это блоки одинакового размера, а что если добавить в блок размер?
Так появился free list-аллокатор, который, по сравнению с предыдущим, не накладывает никаких ограничений на размер блока. Можно выделять и освобождать память в произвольном порядке и любого размера, но, конечно, за это приходится платить. Из-за своей природы производительность этого аллокатора ниже, но другие мудрые люди решили и эту задачку, но об этом позже.
Работает просто и быстро. Каждый свободный блок содержит метаданные (размер, указатель на следующий блок). При выделении памяти ищется в списке блок, подходящий по размеру (есть разные стратегии: first-fit, best-fit, worst-fit, next-fit). Если найденный блок слишком большой, он делится на две части — выделенная память и остаток, который добавляется обратно в список. При освобождении памяти блок возвращается в список, а соседние с ним свободные блоки объединяются, чтобы уменьшить фрагментацию.
Кода тут уже будет порядочно, поэтому оставлю ссылку на одну из реализаций (mtrebi/memory-allocators: FreeListAllocator.cpp).
Из хорошего: позволяет выделять и освобождать блоки памяти в произвольном порядке (в отличие от стекового аллокатора), пытается снижать фрагментацию за счёт объединения свободных блоков; есть возможности для кастомизации и тюнинга.
Из плохого: появляются метаданные для каждого блока; со временем всё равно появятся мелкие несвязные блоки, непригодные для больших запросов; там, где появляются списки и массивы, начинаются проблемы с поиском и объединением блоков, что требует аккуратной реализации.
[Memory Pool]
|-------------------------------| ← Весь пул — один свободный блок
↑
free_list (size=100, next=nullptr)
|##########|--------------------| ← Блок разделился (объект 1)
↑ ↑
Allocated Remaining Free Block
(size=40) (size=56, next=nullptr)
|##########|########|-----------| ← Создали ещё объект 2
↑ ↑ ↑
Alloc1 Alloc2 Free Block
(size=40) (size=20)(size=32)
|----------|########|-----------| ← Удалили объект 1
↑ ↑ ↑
Free Alloc2 Free
(size=40) (size=20)(size=32)
|----------|########|###########| ← Создали объект 3, который не влезает в свободный блок 1
↑ ↑ ↑
Free Alloc2 Alloc3Интересное по теме: gingerbill: free list allocator, embeddedartistry: implementing malloc.
Arena Allocator (Region-Based Allocator)

Что будет, если один большой linear-allocator разбить на несколько поменьше и завязать очистку на количество объектов? А получим мы очень интересную возможность — автоматически сбрасывать текущий участок, если там не осталось живых объектов (все гладиаторы погибли, арена готова принять новых).
Для реализации надо будет следить за счётчиком объектов на этом участке. Арена-аллокатор (region-аллокатор) — это стратегия управления памятью, при которой она выделяется достаточными блоками (аренами) и освобождается автоматически, когда на арене не осталось объектов.
Хороший выбор для алгоритмов и логики, где время жизни объектов предсказуемо и группируется (например, обработка запросов, парсинг данных, игровые кадры), но достаточно большое, что не позволяет их размещать в одном linear-аллокаторе.
// Арены со счётчиком объектов
struct Arena {
void* memory; // Указатель на блок памяти
size_t size; // Общий размер арены
size_t used; // Использовано памяти
int active_objects; // Счётчик активных объектов
Arena(size_t block_size)
: memory(malloc(block_size)), size(block_size), used(0), active_objects(0) {}
~Arena() {
free(memory);
}
bool can_allocate(size_t size, size_t alignment) const {
size_t adjust = alignment - (used % alignment);
adjust = (adjust == alignment) ? 0 : adjust;
return (used + adjust + size) <= this->size;
}
};
class ArenaAllocator {
private:
std::vector<std::unique_ptr<Arena>> arenas;
size_t default_arena_size;
public:
ArenaAllocator(size_t default_size = 4096)
: default_arena_size(default_size) {}
// Выделение памяти с привязкой к арене
void* allocate(size_t size, size_t alignment = alignof(std::max_align_t)) {
// Поиск арены с достаточным свободным местом
for (auto& arena : arenas) {
if (arena->can_allocate(size, alignment)) {
return allocate_in_arena(*arena, size, alignment);
}
}
// Создаём новую арену, если нет подходящей
auto new_arena = std::make_unique<Arena>(default_arena_size);
arenas.push_back(std::move(new_arena));
return allocate_in_arena(*arenas.back(), size, alignment);
}
// Освобождение объекта (уменьшает счётчик и сбрасывает арену при необходимости)
static void deallocate(void* ptr) {
Arena* arena = get_arena_from_pointer(ptr);
arena->active_objects--;
// Если объектов не осталось, сбрасываем арену
if (arena->active_objects == 0) {
arena->used = 0; // Память готова для новых выделений
}
}
private:
// Внутреннее выделение в конкретной арене
void* allocate_in_arena(Arena& arena, size_t size, size_t alignment) {
size_t adjust = alignment - (arena.used % alignment);
adjust = (adjust == alignment) ? 0 : adjust;
assert(arena.used + adjust + size <= arena.size && "Arena overflow");
void* ptr = static_cast<char*>(arena.memory) + arena.used + adjust;
arena.used += adjust + size;
arena.active_objects++;
return ptr;
}
// Получение арены из указателя (заголовок объекта)
static Arena* get_arena_from_pointer(void* ptr) {
return reinterpret_cast<Arena*>(static_cast<char*>(ptr) - sizeof(Arena*));
}
};Если вы заметили — арена не хранит список объектов, при выделении памяти поинтер создаётся со смещением на размер указателя на арену. Это позволит при удалении объекта из такого аллокатора сместиться от поинтера на размер указателя и получить адрес арены, где надо уменьшить счётчик. При достижении 0 будем считать, что все гладиаторы на арене убились и её можно использовать заново; если же память на арене закончилась, то создаём новую арену.
Интересное по теме: gingerbill: arena allocator, tsoding/arena.
Segregated Allocator

Опять же, это очередная попытка выжать больше из linear-аллокатора, ближе к стратегии управления памятью. Добавляем логику для аллокатора, при которой автоматически разделяем память на несколько крупных пулов (сегментов), каждый из которых предназначен для выделения блоков определённого размера.
Чтобы сильно не мельчить, будем создавать пулы для объектов не меньше 16 байт и кратных этому размеру — такой подход позволит получить все преимущества linear-аллокатора и небольшие затраты на управление пулами. Аллокатор всегда знает, в каком сегменте искать подходящий блок: при запросе памяти определяется размер блока, если он соответствует одному из сегментов, аллокатор берёт блок из соответствующего пула, если в пуле нет свободных блоков или нет подходящего пула, выделяется новый.
+-------------------+ +-------------------+ +-------------------+
| Пул 16 байт | | Пул 32 байта | | Пул 64 байта |
| [ ][ ][ ]... | --> | [ ][ ]... | --> | [ ]... |
+-------------------+ +-------------------+ +-------------------+В движке Unreal Engine/CryEngine такие аллокаторы применяются для управления памятью для объектов уровня. Хороший аллокатор, который при правильном подходе позволяет избежать дырок, выделяет свободный блок за O(1), располагает объекты одного типа рядом, улучшая кэширование. К недостаткам можно отнести частичное заполнение самих пулов.
Как показывает практика использования в CryEngine, он позволяет достичь стабильной (не обязательно хорошей, но прогнозируемой) производительности даже на слабом железе. Однако его эффективность напрямую зависит от правильной настройки сегментов и анализа паттернов использования памяти.
При определённых паттернах выделения и освобождения памяти может страдать от высокой фрагментации. Например, в Crysis деревья были реализованы как стволы, с рандомной генерацией положения веток, размеров и листьев. Использовались различные базовые формы веток с разным количеством треугольников (от 1 до 6) для оптимизации производительности, а внутренние части деревьев заполнялись простыми ветками из одного треугольника для создания плотности.
В отличие от SpeedTree, который генерирует деревья процедурно, Crysis использовал ручное моделирование в сочетании с шейдерами для достижения высокого качества, но такой подход приводил к перегрузке этого механизма и сильной просадке FPS в лесу (где каждое дерево было отдельным объектом).

(Видео про растительность в Crysis можно посмотреть в оригинале статьи на Habr.)
В CryEngine2 появилась система Merged Mesh, которая объединяла отдельные объекты растительности в батчи для уменьшения количества draw calls, и система лодов, что позволило более эффективно рендерить большие объёмы растительности, но это уже другая история и другие аллокаторы.
Интересное по теме: GPU Gems 3: Vegetation in Crysis, giamo/segregated-fits-memory-allocator.
Buddy allocator

Алгоритм управления памятью, разработанный в 1960-х годах для операционных систем и файловых хранилищ. Принцип был описан в работах о «теории портфеля» Гарри Марковицем, американским экономистом, и позже в работах Kenneth C. Knowlton как способ борьбы с внешней фрагментацией памяти. Основная идея — разделение памяти на блоки, размеры которых кратны степеням двойки (например, 64, 128, 256 байт). При выделении памяти блок делится на два равных «блока» (buddies), а при освобождении — объединяется обратно. Процесс продолжается вверх по уровням, пока возможно объединение.
Buddy-аллокатор часто используется в игровых движках для управления ресурсами, где требуется быстрое долговременное выделение памяти с минимальной фрагментацией: текстуры и меши (ресурсы часто имеют размеры, кратные степеням двойки — 512×512, 1024×1024, в Unreal Engine используется для управления видеопамятью), звуковые буферы, физические объекты (коллайдеры и данные в Havok), долгосрочные объекты уровня, spatial-объекты и октодерево для разделения пространства уровня (например, в id Tech 4, Doom 3).
Уровень 0: [Свободен]
[===================================] ← Блок размером 1024 байта (2^10)
^
Запрос на выделение 256 байт (2^8)
[=================|=================] ← Уровень 1: 2 блока по 512B
[########| | | ] ← Уровень 3: 1 блок занят (256B)
^
Выделенная память
Запрос на выделение 128 байт (2^7)
[=================|=================] ← Уровень 1: 2 блока по 512B
[########| | | ] ← Уровень 3: 1 блок занят (256B)
[########|####|...|........|........]
^
Выделено 128B
Освобождение блока 256B
[........|####|...|........|........]
^
Занято 128BИнтересное по теме: Wikipedia: Buddy memory allocation, gingerbill: buddy allocator, bitsquid buddy allocator design.
Thread-Cache Allocator

Как, наверное, понятно из названия, это стратегия управления памятью, направленная на минимизацию конкуренции за ресурсы между потоками. Системный new/malloc взаимодействует с операционной системой для выделения и освобождения памяти. Когда приложение запрашивает память, то в худшем случае ему приходится конкурировать за ресурсы с другими приложениями. Сначала проверяется, есть ли свободная память во внутренних пулах процесса, если её недостаточно, то идёт обращение через системные вызовы brk/VirtualAlloc, которые запрашивают память у ядра ОС.
TC-аллокатор переносит работу с памятью на уровень отдельного потока, предоставляя каждому собственный пул памяти. Помимо избавления от системного new/malloc, он также снижает затраты на синхронизацию между потоками.
В идеальном случае каждый поток имеет свой собственный пул памяти, что позволяет избежать блокировок и уменьшить накладные расходы на синхронизацию. Если локальный пул оказывается исчерпан, аллокатор обращается к общему пулу между потоками (если он есть), а если и тот закончился, то уже обращается к стандартным механизмам new/delete. Чтобы снизить возможные издержки, запрошенная память не возвращается процессу, а остаётся в локальном пуле потока.
class ThreadCacheAllocator {
public:
ThreadCacheAllocator() {
// Инициализация центральной кучи
}
void* allocate(size_t size) {
// Получаем локальный кэш для текущего потока
auto& cache = getThreadCache();
// Есть ли свободная память в локальном кэше
if (cache.freeList.empty()) {
// Если кэш пуст, запрашиваем память из центральной кучи
cache.freeList = fetchFromCentralHeap(size);
}
// Выделяем память из локального кэша
void* ptr = cache.freeList.back();
cache.freeList.pop_back();
return ptr;
}
void deallocate(void* ptr, size_t size) {
// Возвращаем память в локальный кэш
auto& cache = getThreadCache();
cache.freeList.push_back(ptr);
}
private:
struct ThreadCache {
std::vector<void*> freeList; // Список свободных блоков памяти
};
// Получаем локальный кэш для текущего потока
ThreadCache& getThreadCache() {
thread_local ThreadCache cache;
return cache;
}
// Запрашиваем память из центральной кучи
std::vector<void*> fetchFromCentralHeap(size_t size) {
std::lock_guard<std::mutex> lock(heapMutex);
std::vector<void*> blocks;
// Выделяем несколько блоков памяти
for (int i = 0; i < 10; ++i) {
void* block = malloc(size);
blocks.push_back(block);
}
return blocks;
}
std::mutex heapMutex; // Лок для синхронизации доступа к центральной куче
};Где используется:
- Многопоточный рендеринг: такие аллокаторы позволяют каждому потоку выделять память для вершин, текстур и других данных без конкуренции за ресурсы. В Unreal Engine используется TCMalloc.
- Многопоточная физика: обработка столкновений или движения объектов. В PhysX используется собственный Thread-Cache аллокатор.
- Многопоточная анимация: в Frostbite (движок EA) есть многопоточный менеджер анимаций, и там используется отдельный аллокатор.
Минусов тоже хватает: самый большой — это сложность реализации по сравнению с простыми аллокаторами и необходимость следовать строгим правилам при работе. Не все алгоритмы позволяют работать в таком режиме. Thread-Cache аллокаторы имеют большие накладные расходы, особенно если используются большие блоки памяти. Высокий риск утечек и других проблем при невнимательной работе.
Интересное по теме: mjansson/rpmalloc, tcmalloc design.
Fibonacci allocator

Аллокатор использует последовательность чисел Фибоначчи для управления блоками памяти. Числа Фибоначчи — это последовательность, где каждое число равно сумме двух предыдущих: 1, 1, 2, 3, 5, 8, 13, 21, 34 и так далее. Эти числа используются для определения размеров блоков памяти, что позволяет минимизировать фрагментацию и показывает лучшие результаты при работе со строками естественных языков. Фрагментация на таких данных с аллокатором Фибоначчи на 40% ниже, чем с дефолтным, и почти на 80% по сравнению с buddy-аллокатором.
Предложения естественных языков имеют разную длину, но часто их размеры укладываются в определённые диапазоны (короткие слова, фразы или предложения). Числа Фибоначчи лучше соответствуют этим диапазонам, чем степени двойки, минимизируя внутреннюю фрагментацию. Также числа Фибоначчи растут медленнее, чем степени двойки, что делает их подходящими для распределения памяти, когда преобладают небольшие и средние объёмы данных (до 2 Кб).
class FibonacciAllocator {
public:
FibonacciAllocator() {
// Свободные блоки
for (size_t size : fibonacciSizes) {
freeBlocks[size] = std::vector<void*>();
}
}
void* allocate(size_t size) {
// Ближайшее число Фибоначчи, большее или равное запрошенному размеру
size_t fibSize = findFibonacciSize(size);
// Есть ли свободные блоки нужного размера
if (!freeBlocks[fibSize].empty()) {
void* ptr = freeBlocks[fibSize].back();
freeBlocks[fibSize].pop_back();
return ptr;
}
// Свободных блоков нет, выделяем новый
void* ptr = malloc(fibSize);
if (!ptr) {
throw std::bad_alloc();
}
return ptr;
}
void deallocate(void* ptr, size_t size) {
size_t fibSize = findFibonacciSize(size);
// Возвращаем блок
freeBlocks[fibSize].push_back(ptr);
}
private:
std::vector<size_t> fibonacciSizes = {1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144};
// Список свободных блоков для каждого размера
std::unordered_map<size_t, std::vector<void*>> freeBlocks;
size_t findFibonacciSize(size_t size) {
for (size_t fibSize : fibonacciSizes) {
if (fibSize >= size) {
return fibSize;
}
}
assert(false); // Запрошен слишком большой блок
}
};Интересное по теме: dev.to: generalized Fibonacci memory allocator, naens/mem_alloc.
Compacting allocator

Фрагментация памяти — одна из больных тем в долгоживущих приложениях, не только в играх. Как бы хорош ни был аллокатор общего назначения, со временем выделение и освобождение памяти приводит к появлению «дырок» и снижает эффективность использования памяти. Для текущего поколения игр и консолей допустимым является 5% фрагментации в первый час игры и +2% на каждый следующий час. Это 7% от 16 Гб, условно, которую заняла игра — сколько это будет в худшем случае? 16 Гб × 0.07 = 1.12 Гб, да у меня на ПК было меньше лет 10 назад. А на консолях не то что 1 Гб потерять нельзя, там счёт иногда на 10 мегабайт идёт.
Такой аллокатор должен решать эту проблему за счёт периодического перемещения объектов в памяти, собирая свободное пространство в единый блок, перемещая объекты так, чтобы все занятые блоки располагались непрерывно. Чем-то напоминает дефрагментацию жёсткого диска, но выполняется программно и в реальном времени.
void rminit(void *heap, size_t heap_size);
handle_t rmmalloc(size_t nbytes);
void rmfree(handle_t *handle);
void *lock(handle_t handle);
void unlock(handle_t handle);
void compact(uint32_t compact_time_max_ms);Здесь handle_t — это неявный тип (opaque type), который позволяет получить фактический указатель на память, связанный с дескриптором (handle). Для этого нужно вызвать дополнительную функцию lock(), которая и возвращает обычный указатель на память. Из примеров можно привести Unity и Godot, которые используют компактинг, причём не только на уровне .NET-кода, но и для некоторых внутренних структур движка. Минусы — паузы при компактизации, дополнительный уровень абстракции и потери в производительности, хэндлы вместо указателей.
Интересное по теме: plasma-umass/Mesh, mmtk/mmtk-core, ivmai/bdwgc.
Hot/Cold splitting allocator

Сущности и объекты в играх содержат сотни полей, из которых только 10–20% активно используются в работе и обновляются каждый кадр, а остальные лежат мёртвым грузом в памяти, обновляясь раз в несколько секунд или вообще один раз за сессию. Суть заключается в том, чтобы подсказать компилятору, какие из свойств будут обновляться чаще других, чтобы он автоматически размещал их ближе к началу объекта в памяти (если это POD-структуры) или в специальных областях — соответственно, холодное и горячее хранилище.
struct Entity {
// Горячие данные (обновляются каждый кадр)
[[hot]] Vec3 position;
[[hot]] Matrix rotation;
[[hot]] float health;
// Холодные данные (обновляются редко)
[[cold]] xstring configPath;
[[cold]] TextureID legacyTexture;
};В плюсах программист сам может подвигать эти данные, чтобы они были ближе к началу объекта, но из-за иерархии объектов это не всегда можно сделать оптимально.
Пока что в таких исследованиях замечены только Bungie с их Destiny 2: advances.realtimerendering.com/destiny, GDC: Multithreading the Entire Destiny.
TLSF (Two-Level Segregated Fit)

Наверное, лучший и очень быстрый аллокатор общего назначения для игр, с которым приходилось работать (используется в Uncharted, Metro, Halo, Horizon, Mafia, The Witcher 3). Аллокатор возвращает наименьший блок памяти, который достаточно велик для размещения объекта. Поскольку большинство объектов занимают блоки памяти в ограниченном диапазоне размеров, стратегия Best-Fit (или её упрощённая версия — Good-Fit) обычно приводит к наименьшей фрагментации памяти при реальных нагрузках по сравнению с другими подходами, такими как First-Fit.
Как работает: делим нашу память на два уровня, класс памяти (кратно степеням двойки), это позволяет быстро определить, к какому классу относится запрашиваемый размер. Далее внутри каждого класса память делится на подкатегории, например для класса 128–256 байт пусть будет 128–160, 161–200, 201–232, 233–256.
Далее для поиска используется битовая маска, чтобы понять, есть ли свободные блоки в определённой категории. Например, если в категории 128–256 байт есть свободные блоки, соответствующий бит будет равен 1. Это позволяет быстро найти нужный класс и спуститься на второй уровень, где другая битовая маска определяет уточнённый размер. Условные 202 байта попадают в третью подкатегорию, из которой возвращается первый свободный блок. Никаких переборов и итераций.
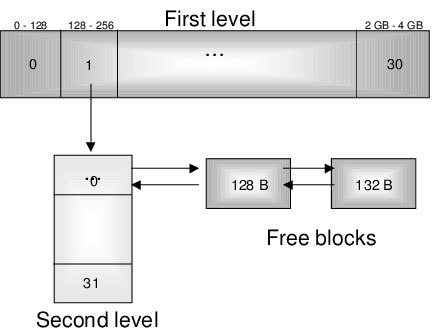
- Каждый список содержит свободные блоки, размеры которых находятся в пределах одного класса размеров (диапазона).
- Блоки внутри каждого списка не упорядочены, что упрощает и ускоряет операции.
- Стратегия Good-Fit позволяет реализовать эффективный и предсказуемый алгоритм управления памятью.
- Операции поиска свободного блока выполняются за O(1), благодаря предварительной организации памяти в классы размеров.
Небольшой бенчмарк, который я проводил для аллокаторов на одном из проектов, просто для понимания скорости работы (в тактах процессора):
Size malloc malloc DL's Binary TLSF
(First-Fit) (Best-Fit) malloc Buddy
128 25636 112566 7376 4140 155
243 22124 91216 5660 4448 168
512 15974 82162 5445 4248 159
4097 14743 65661 3346 4135 162Интересное по теме: rmind/tlsf, gii.upv.es/tlsf, reverberate: one malloc to rule them all.
Всё?
Да нет, конечно. Это просто те, с которыми пришлось столкнуться в проектах. Расскажете о своём опыте работы с аллокаторами?
← Все статьи