

Games often use the pattern of packing boolean values into bits. It's handy for optimizing memory and speeding up bulk checks. For example, such checks might include whether a player is in a tile, determining cell availability on a four- or six-sided grid, or other spatial checks that have to run fast. It's not rocket science, but when the profiler showed one of these functions among the hot ones, I got curious about how exactly it works and whether it could be optimized. The bitset data structure is a way to efficiently represent a set of integer indices, which on top of that supports various operations over it — for example union, difference, intersection.
So, each unit can occupy one or several tiles, especially if it's a big unit like a chariot or a trebuchet, and we want to build a derived map that stores other attributes — for example: is there a unit in this tile, or a filter by unit health. Such maps are used for various quick checks, like: can you move to a point, or which units are worth attacking.
To represent the data we can use the unit's index in the tile. As a typical task, we'll only check units whose health exceeds a certain value. This condition isn't picked out of thin air. For example, some units use strategies like "kill the weakest" or "attack in a pack." For such strategies, a per-unit walk over all the units around (especially if every unit in the group does it) can become a very time-consuming operation.
The title came about more or less on its own: not far from my place there's a nice café, Chief&Bites, fairly popular with the locals, but they only start making the pastries after you order — an anti-café format of sorts. As you can imagine, waiting half an hour, or even an hour, for the freshest pastry is easy; they even print on the receipt the time they started making your particular pastry. Apologies in advance for the possible "reinvented wheels" in the code, but maybe someone will find the topic useful.
As long as you don't think about packing booleans, they don't bother you. I was pushed onto this topic by QA, who sent some rather strange reports that on certain benchmark maps the tests catch microfreezes when units move: you won't see it with your eyes, but there's an unpleasant feeling that the game is "floating," even though the fps stays high. And it only showed up on certain map sizes and under certain conditions — more on that later.
Let's get back to our algorithm, which in its simplest form looks something like this:
array length: N
unitExist[x][y] = !!(unitHealth[x][y] > limit)
for i = 0...N-1
byte = pack(!!(unitHealth[i] > limit),
!!(unitHealth[i+1] > limit)
...,
!!(unitHealth[i+7] > limit))
output[i/8] = byte
i += 8And when bit packing is used, it also lets you save memory — that was the original idea.
256 x 256 * 1 (byte/health) = 65536 (bytes) = 64kb
64kb/8 = 8192 (bytes) = 8kbI'll only describe the part related to "packing." Working with such values requires other algorithms, and sometimes that extra work can substantially slow down the whole process. The problem is similar to compression algorithms, though packing is usually a much faster process. These days the conflict between memory footprint and computing power isn't as acute as, say, twenty years ago, so the choice of what to trade for what is left to the developer.
Who are we measuring bits against?
To have something to compare with, I'll take a few well-established solutions; each has its pros and cons. And speed isn't always the deciding factor, but in my case it was the main criterion. Let me explain a bit how this part of the code even showed up in the profiler. The original algorithm used a naive placement of bools in memory — relatively fast and simple to implement, but in a fit of refactoring it was replaced with std::bitset, which ended up making it flicker periodically in the profile reports.
- No packing: just store the boolean values.
std::bitset.std::vector<bool>.- One "manual" variant.
- Community implementations.
At first I tried running on live data like maps from a certain well-known strategy game, but then I realized that random data or just noise gives similar results when comparing their run times, so the initial data will be this set:
uhealths.reset(new int[N]);
exist.reset(new bool[N]);
length = N;
std::mt19937 gen(0);
std::uniform_int_distribution<> dist(0, 255);
for (size_t i = 0; i < testLength; ++i) {
uhealths[i] = dist(gen);
exist[i] = (uhealths[i] > limit);
}std::bitset
The first drawback of using std::bitset is that it requires a compile-time-known constant N. This means that if the bitset's size can change at runtime, std::bitset becomes impractical, and you have to use alternatives such as std::vector<bool> or your own bit-array implementations.
The second is vendor lock-in: std::bitset depends on the implementation of a particular SDK, which can affect performance or even correctness depending on the platform and compiler. For example, some implementations may not be sufficiently optimized for bulk bit work, which makes std::bitset less preferable when used in hot functions. For this reason, in most engines using std::bitset is not recommended, and developers exercise themselves describing their own cacti.
The advantage of this class is that it's part of the standard library and is well debugged and tested.
for (int64_t i = 0; i < length; ++i)
exist_bs.set(i, !!(uhealths[i] > limit));std::vector<bool>
std::vector<bool> is a specialized implementation of the standard std::vector container where, instead of allocating one byte of memory per element, they're packed into bits, which saves memory. However, this optimization has its drawbacks that make std::vector<bool> less suitable for use. One drawback is the lack of container semantics — the class doesn't provide direct access to its elements as references (bool&). Instead it uses proxy objects, and read and write operations become less efficient due to the need to work through the proxy. Some standard-library algorithm implementations can't work, or work more slowly, because of the missing reference semantics.
But the main problem is the poor predictability of run time if inserting an element triggers a reallocation of the array. Many people forget about this when designing the logic.
for (int64_t i = 0; i < arrayLength; ++i)
exist_vb[i] = !!(uhealths[i] > health);The naive version
std::vector<uint8_t> is a standard container often used for working with sets of boolean values when you need high performance, simplicity of implementation, and predictable behavior. Unlike std::vector<bool>, it doesn't try to pack values into bits but stores each element as a separate byte (8 bits). Simplicity — it works like an ordinary byte array, providing direct access to elements, including the ability to use references (uint8_t&); good performance — the minimal overhead among all the classes; and compatibility with all algorithms makes this class the best choice for a game engine. I can also note the minimal differences between implementations across virtually all SDKs, which makes it predictable and identical on all platforms. On the downside — the need to carry a relatively large amount of data in the unit, 80% of which is never used.
auto uhealths = health.get();
auto pOutputByte = vector<uint8_t>::data();
for (int i = 0; i < testLen; ++i) {
*pOutputByte = (*uhealths > limit);
pInputData++;
pOutputByte++;
}ce::bitset
The solution is taken from the CryEngine engine (github.com/ValtoGameEngines/CryEngine) — pretty and simple. The sources are fairly old; I unfortunately couldn't find anything newer. We have N/8 full bytes, plus one byte at the end that may be partially filled. At its core, as usual, is the use of a uint8_t array that stores the bit information.
The pros of the solution: efficiency — a minimal number of bytes is used; and simplicity — the code is simple and easily adapted to various needs, for example checking other unit states like lifetime, status, or other flags. Two optimization patterns are used here — loop unrolling, where instead of working with one variable, eight different variables are used to store the condition result, and CPU data parallelism: at the CPU's discretion these variables can be executed in arbitrary order or simultaneously, if it has the registers to perform concurrent operations.
By using independent variables, the Crysis authors managed to speed things up nicely and even beat the no-packing version on speed! As you understand, this topic is fairly widely covered and researched, and you may have run into it at conferences.

Benchmarks
Here are a few more open-source libraries I've used across different projects and engines.
- CRoaring: implements the compressed Roaring format in C with a C++ wrapper. Works with GCC, clang and Visual Studio.
- EWAHBoolArray: implements the compressed EWAH format in C++. A C version of this library is partly included in Git — a tool everyone knows. Similar to WAH and Concise, but faster.
- cbitset: implements an uncompressed bitset in C. Works with GCC and clang.
- Concise: this C++ library implements the compressed WAH and CONCISE formats. Works with GCC and clang.
- BitMagic: this C++ library uses its own compression format. Somewhat similar to Roaring, but may use more memory. Works with GCC, clang and Visual Studio.
constexpr int N = 1 << 22;
constexpr int testLen = N;
const int length = N;
int* ids = nullptr;
uint8_t * exist = nullptr;
std::vector<uint8_t> exist_rbyte;
std::vector<bool> exist_vb;
uint8_t* exist_cr = nullptr;
uint8_t *exist_cr_sse4 = nullptr;
std::bitset<N> exist_bs;
bool init_data = [] {
ids = (int*)_aligned_malloc(N * 4, 16);
exist = new uint8_t[N];
exist_vb.resize(N);
int numBytes = (N + 7) / 8;
exist_cr = new uint8_t[numBytes];
exist_cr_sse4 = (uint8_t *)_aligned_malloc(numBytes, 16);
std::mt19937 gen(0);
std::uniform_int_distribution<> dist(0, 255);
for (int i = 0; i < length; ++i) {
ids[i] = dist(gen);
}
return true;
} ();Test run times
BM_NaivePack/1 1609942 ns
BM_NaivePack/16 1192141 ns
BM_NaivePack/31 1719096 ns
BM_NaivePack/46 1200694 ns
BM_NaivePack/61 1618988 ns
BM_NaivePack/76 2186776 ns
BM_NaivePack/91 2802234 ns
BM_NaivePack/106 2662890 ns
BM_NaivePack/121 2073261 ns
BM_NaivePack/136 2634842 ns
BM_NaivePack/151 3746350 ns
BM_NaivePack/166 3394095 ns
BM_NaivePack/181 4359031 ns
BM_NaivePack/196 3435947 ns
BM_NaivePack/211 3510137 ns
BM_NaivePack/226 3655667 ns
BM_NaivePack/241 3991442 ns
BM_NaivePackBytes/1 3509043 ns
BM_NaivePackBytes/16 3514472 ns
BM_NaivePackBytes/31 3678914 ns
BM_NaivePackBytes/46 3544597 ns
BM_NaivePackBytes/61 3633955 ns
BM_NaivePackBytes/76 3617636 ns
BM_NaivePackBytes/91 3584735 ns
BM_NaivePackBytes/106 3617619 ns
BM_NaivePackBytes/121 3723257 ns
BM_NaivePackBytes/136 3577626 ns
BM_NaivePackBytes/151 3612330 ns
BM_NaivePackBytes/166 3645496 ns
BM_NaivePackBytes/181 3505923 ns
BM_NaivePackBytes/196 3545582 ns
BM_NaivePackBytes/211 3575154 ns
BM_NaivePackBytes/226 3576095 ns
BM_NaivePackBytes/241 3493394 ns
BM_BitsetPack/1 6674177 ns
BM_BitsetPack/16 6621221 ns
BM_BitsetPack/31 7335433 ns
BM_BitsetPack/46 6981509 ns
BM_BitsetPack/61 11823524 ns
BM_BitsetPack/76 11110423 ns
BM_BitsetPack/91 11182558 ns
BM_BitsetPack/106 14577181 ns
BM_BitsetPack/121 15940045 ns
BM_BitsetPack/136 15685271 ns
BM_BitsetPack/151 14161470 ns
BM_BitsetPack/166 14417320 ns
BM_BitsetPack/181 12599843 ns
BM_BitsetPack/196 10681116 ns
BM_BitsetPack/211 7695923 ns
BM_BitsetPack/226 9137301 ns
BM_BitsetPack/241 7174469 ns
BM_VectorBoolPack/1 5458234 ns
BM_VectorBoolPack/16 6592367 ns
BM_VectorBoolPack/31 8488209 ns
BM_VectorBoolPack/46 9434079 ns
BM_VectorBoolPack/61 10114762 ns
BM_VectorBoolPack/76 10074691 ns
BM_VectorBoolPack/91 9704196 ns
BM_VectorBoolPack/106 8232093 ns
BM_VectorBoolPack/121 8646065 ns
BM_VectorBoolPack/136 8656318 ns
BM_VectorBoolPack/151 8223281 ns
BM_VectorBoolPack/166 7549834 ns
BM_VectorBoolPack/181 6153987 ns
BM_VectorBoolPack/196 5565482 ns
BM_VectorBoolPack/211 5112986 ns
BM_VectorBoolPack/226 6735515 ns
BM_VectorBoolPack/241 6374604 ns
BM_VectorBoolCrPack/1 862798 ns
BM_VectorBoolCrPack/16 961743 ns
BM_VectorBoolCrPack/30 1463229 ns
BM_VectorBoolCrPack/31 1663319 ns
BM_VectorBoolCrPack/32 1763199 ns
BM_VectorBoolCrPack/46 970211 ns
BM_VectorBoolCrPack/61 1866960 ns
BM_VectorBoolCrPack/62 1966960 ns
BM_VectorBoolCrPack/63 1766960 ns
BM_VectorBoolCrPack/76 960931 ns
BM_VectorBoolCrPack/91 970822 ns
BM_VectorBoolCrPack/106 930512 ns
BM_VectorBoolCrPack/127 1445005 ns
BM_VectorBoolCrPack/128 1478082 ns
BM_VectorBoolCrPack/129 1421018 ns
BM_VectorBoolCrPack/136 1073085 ns
BM_VectorBoolCrPack/151 1022925 ns
BM_VectorBoolCrPack/166 1098550 ns
BM_VectorBoolCrPack/181 1069320 ns
BM_VectorBoolCrPack/196 869055 ns
BM_VectorBoolCrPack/211 864756 ns
BM_VectorBoolCrPack/226 869617 ns
BM_VectorBoolCrPack/241 873865 ns
BM_VectorRoaringPack/1 4275220 ns
BM_VectorRoaringPack/16 5437126 ns
BM_VectorRoaringPack/31 6128085 ns
BM_VectorRoaringPack/46 5871086 ns
BM_VectorRoaringPack/61 7915343 ns
BM_VectorRoaringPack/76 7712348 ns
BM_VectorRoaringPack/91 9502761 ns
BM_VectorRoaringPack/106 10350658 ns
BM_VectorRoaringPack/121 11880587 ns
BM_VectorRoaringPack/136 13258820 ns
BM_VectorRoaringPack/151 8353258 ns
BM_VectorRoaringPack/166 7489464 ns
BM_VectorRoaringPack/181 6191120 ns
BM_VectorRoaringPack/196 5471773 ns
BM_VectorRoaringPack/211 4170502 ns
BM_VectorRoaringPack/226 4265632 ns
BM_VectorRoaringPack/241 4382265 ns
BM_VectorEWAHPack/1 1300556 ns
BM_VectorEWAHPack/16 1577675 ns
BM_VectorEWAHPack/31 1944834 ns
BM_VectorEWAHPack/46 2320396 ns
BM_VectorEWAHPack/61 2747305 ns
BM_VectorEWAHPack/76 3173199 ns
BM_VectorEWAHPack/91 3641935 ns
BM_VectorEWAHPack/106 4138737 ns
BM_VectorEWAHPack/121 4518641 ns
BM_VectorEWAHPack/136 5495677 ns
BM_VectorEWAHPack/151 4214512 ns
BM_VectorEWAHPack/166 3771664 ns
BM_VectorEWAHPack/181 3325077 ns
BM_VectorEWAHPack/196 2797083 ns
BM_VectorEWAHPack/211 2260267 ns
BM_VectorEWAHPack/226 2653270 ns
BM_VectorEWAHPack/241 2997353 ns
BM_VectorBoolCrPack16/1 954375 ns
BM_VectorBoolCrPack16/16 1039411 ns
BM_VectorBoolCrPack16/31 1002091 ns
BM_VectorBoolCrPack16/46 1028297 ns
BM_VectorBoolCrPack16/61 1000939 ns
BM_VectorBoolCrPack16/76 1026647 ns
BM_VectorBoolCrPack16/91 1042885 ns
BM_VectorBoolCrPack16/106 1032887 ns
BM_VectorBoolCrPack16/121 1012283 ns
BM_VectorBoolCrPack16/136 1032231 ns
BM_VectorBoolCrPack16/151 1015109 ns
BM_VectorBoolCrPack16/166 1002528 ns
BM_VectorBoolCrPack16/181 992190 ns
BM_VectorBoolCrPack16/196 974831 ns
BM_VectorBoolCrPack16/211 1010501 ns
BM_VectorBoolCrPack16/226 1112051 ns
BM_VectorBoolCrSSE4Slow/1 2107951 ns
BM_VectorBoolCrSSE4Slow/16 2560582 ns
BM_VectorBoolCrSSE4Slow/31 2607340 ns
BM_VectorBoolCrSSE4Slow/46 2728132 ns
BM_VectorBoolCrSSE4Slow/61 2643938 ns
BM_VectorBoolCrSSE4Slow/76 2667886 ns
BM_VectorBoolCrSSE4Slow/91 2629916 ns
BM_VectorBoolCrSSE4Slow/106 2786141 ns
BM_VectorBoolCrSSE4Slow/121 2816921 ns
BM_VectorBoolCrSSE4Slow/136 2832634 ns
BM_VectorBoolCrSSE4Slow/151 2824516 ns
BM_VectorBoolCrSSE4Slow/166 2734794 ns
BM_VectorBoolCrSSE4Slow/181 2786650 ns
BM_VectorBoolCrSSE4Slow/196 2808093 ns
BM_VectorBoolCrSSE4Slow/211 2796277 ns
BM_VectorBoolCrSSE4Slow/226 2780945 ns
BM_VectorBoolCrSSE4Slow/241 2750617 ns
BM_VectorBoolCrSSE4/1 444404 ns
BM_VectorBoolCrSSE4/16 451969 ns
BM_VectorBoolCrSSE4/31 522670 ns
BM_VectorBoolCrSSE4/46 467582 ns
BM_VectorBoolCrSSE4/61 475176 ns
BM_VectorBoolCrSSE4/76 458831 ns
BM_VectorBoolCrSSE4/91 438453 ns
BM_VectorBoolCrSSE4/106 455410 ns
BM_VectorBoolCrSSE4/121 440304 ns
BM_VectorBoolCrSSE4/136 453381 ns
BM_VectorBoolCrSSE4/151 458007 ns
BM_VectorBoolCrSSE4/166 463374 ns
BM_VectorBoolCrSSE4/181 447081 ns
BM_VectorBoolCrSSE4/196 492977 ns
BM_VectorBoolCrSSE4/211 449133 ns
BM_VectorBoolCrSSE4/226 484524 ns
BM_VectorBoolCrSSE4/241 447056 nsFrom what I had on hand while running the tests (CPU comparison), they ran on a single core with affinity set, but Intel still managed to bounce the thread between cores — you could see it in PIX, which is probably also where the run-time dip comes from. AMD didn't bounce the thread, and there were noticeably fewer context switches.
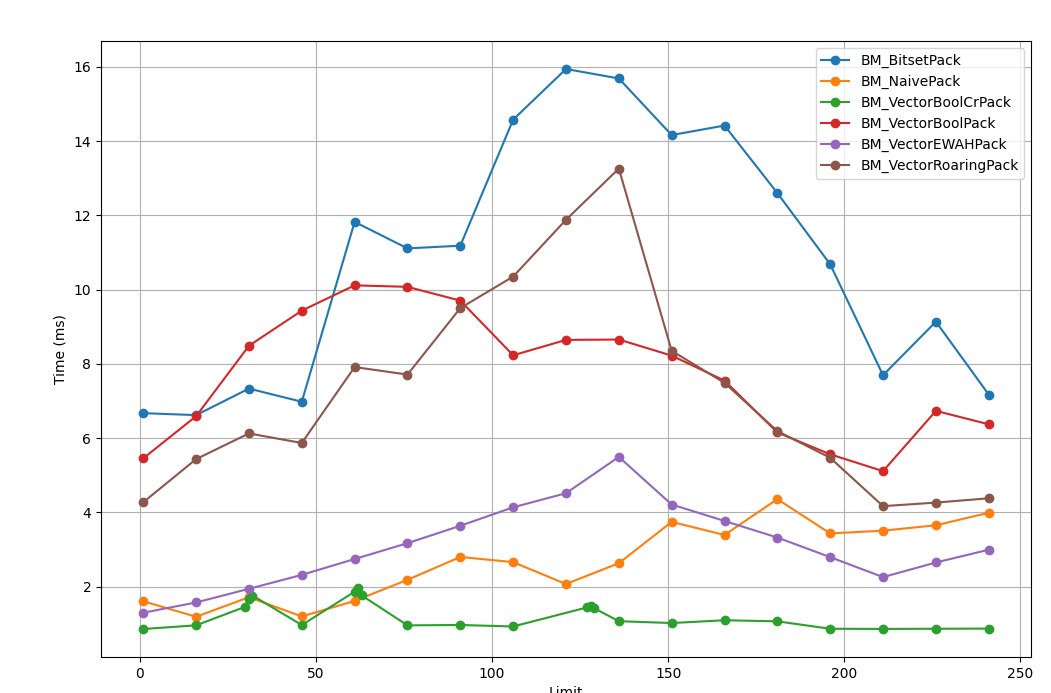
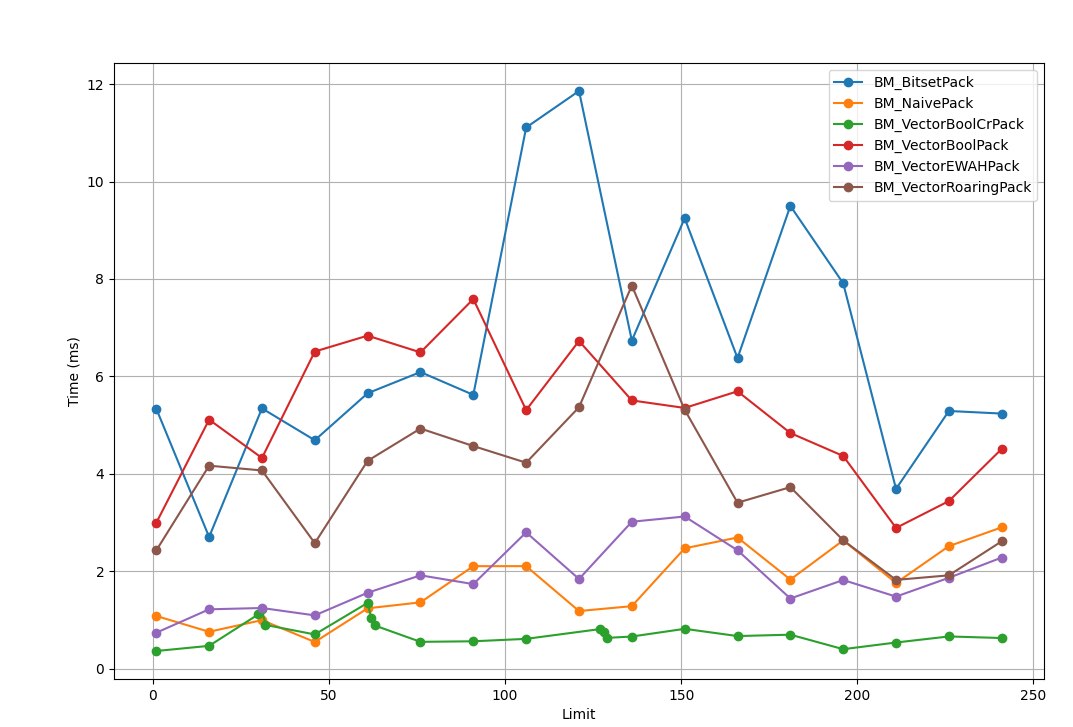
Branches
As you may have already noticed, on the charts all the algorithms reviewed have spikes around 32, 64, 128. I'd guess the problem is mispredicted branches and frequent misses in the branch-prediction unit. When the threshold value is relatively stable, the probability that the input values cause a branch change is relatively low. But for thresholds that are multiples of, or close to, 32, the picture changes, and I can't explain it. Searching for more info on the internets, I stumbled on an interesting, fairly old article (Fast and slow if-statements: branch prediction) on the topic.
For values above 127 you can observe a decrease in the number of branch misses and, accordingly, an increase in speed: the CPU sees from the BPU history that previous branches went the other way. We see the very peak in almost all algorithms near the value of 128; unfortunately, I don't have the tools to measure the CPU's branch misses.
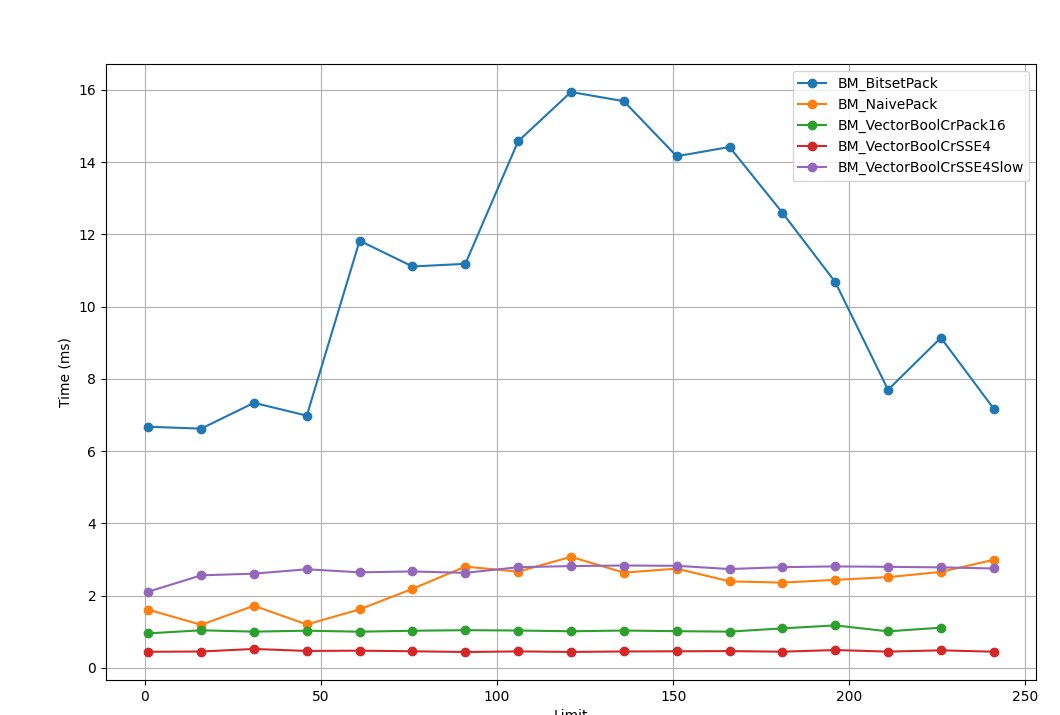
Why the CryEngine algorithm doesn't "glitch"
And you probably have the question of why the CR version is free of these effects and works more or less stably across the whole range. As you can see, the version by the Crysis authors doesn't use branches. Instead it uses the setg instruction (set byte if greater), but that's not a real branch.
typedef unsigned char uint8_t;
void bm_branch(int* uhealths, uint8_t* bm, int len, int limit)
{
uint8_t mask[8] = { 0 };
const auto lenDivBy8 = (len / 8) * 8;
auto h = uhealths;
auto bb = bm;
for (int j = 0; j < lenDivBy8; j += 8)
{
mask[0] = h[0] > limit ? 0x01 : 0;
mask[1] = h[1] > limit ? 0x02 : 0;
mask[2] = h[2] > limit ? 0x04 : 0;
mask[3] = h[3] > limit ? 0x08 : 0;
mask[4] = h[4] > limit ? 0x10 : 0;
mask[5] = h[5] > limit ? 0x20 : 0;
mask[6] = h[6] > limit ? 0x40 : 0;
mask[7] = h[7] > limit ? 0x80 : 0;
*bb++ = mask[0] | mask[1] | mask[2] | mask[3] | mask[4] | mask[5] | mask[6] | mask[7];
h += 8;
}
}godbolt: asm comparison for MS and clang.
So, if I understood the asm correctly, the CR algorithm isn't subject to BPU misses, because it doesn't use branches but uses setg, which doesn't cause a change in control flow the way conditional jumps do.
In the naive version of the code (and, I think, in the other algorithms too) there are branches in the loop, which affects the speed. And when the processor hits a non-patterned jump, on top of relatively random data, all of this leads to a multiple drop in performance.
typedef unsigned char uint8_t;
void bm_branch(int* uhealths, uint8_t* bm, int len, int limit)
{
uint8_t mask = 0;
int shiftl = 0;
auto h = uhealths;
auto bb = bm;
for (int i = 0; i < len; ++i)
{
if (*h > limit)
mask |= (1 << shiftl);
h++;
shiftl++;
if (shiftl > 7)
{
*bb++ = mask;
mask = 0;
shiftl = 0;
}
}
}The same thing but with branches, and the compiler couldn't optimize it, even with a well-known usage pattern. godbolt: version for MS and clang.
Benchmarks aren't a real project
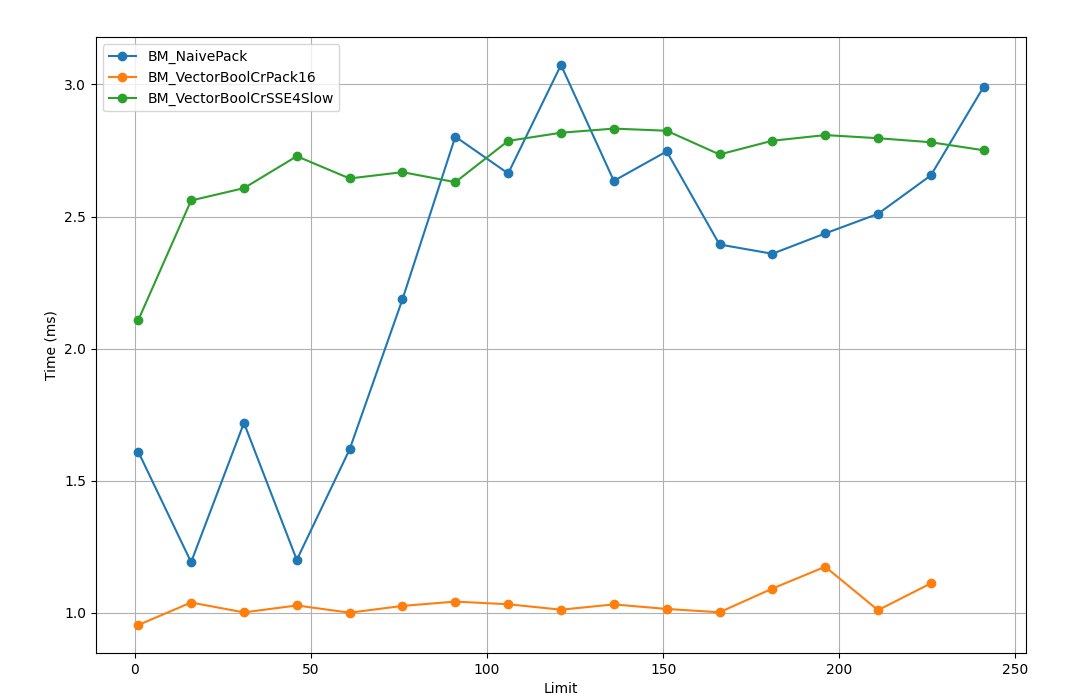
As you understand, benchmarks are a good thing, but a real application imposes its own constraints. So in the game the gain was something around 2% on the tests. We usually don't let production code that yields less than a 3% gain through — except for memory fixes — and it gets sent back for rework, so the possible fix was shelved in the backlog. One colleague at review suggested simply widening the mask range to process more bits at once — that's how the x16 version came about, which of course ran faster, but still didn't give 3%.
int ImplVectorBoolCr16(int *health, uint8_t *pOutput, int limit) {
auto h = (uint8_t*)health;
auto pOutputByte = pOutput;
uint8_t mask[16] = { 0 };
const int64_t lenDivBy16 = (testLen / 16) * 16;
for (int64_t i = 0; i < lenDivBy16; i += 16) {
mask[0] = (*h > limit) ? 0x01 : 0; h++;
mask[1] = (*h > limit) ? 0x02 : 0; h++;
mask[2] = (*h > limit) ? 0x04 : 0; h++;
mask[3] = (*h > limit) ? 0x08 : 0; h++;
mask[4] = (*h > limit) ? 0x10 : 0; h++;
mask[5] = (*h > limit) ? 0x20 : 0; h++;
mask[6] = (*h > limit) ? 0x40 : 0; h++;
mask[7] = (*h > limit) ? 0x80 : 0; h++;
mask[8] = (*h > limit) ? 0x100 : 0; h++;
mask[9] = (*h > limit) ? 0x200 : 0; h++;
mask[10] = (*h > limit) ? 0x400 : 0; h++;
mask[11] = (*h > limit) ? 0x800 : 0; h++;
mask[12] = (*h > limit) ? 0x1000 : 0; h++;
mask[13] = (*h > limit) ? 0x2000 : 0; h++;
mask[14] = (*h > limit) ? 0x4000 : 0; h++;
mask[15] = (*h > limit) ? 0x8000 : 0; h++;
*pOutputByte = mask[0] | mask[1] | mask[2] | mask[3] | mask[4] | mask[5] | mask[6] | mask[7]
| mask[8] | mask[9] | mask[10] | mask[11] | mask[12] | mask[13] | mask[14] | mask[15];
pOutputByte += 2;
}
return *pOutputByte;
}Looking at the resulting code, I figured I could port this algorithm to SSE, and did a straightforward solution, but it ran even slower than the plain C++ code.
int ImplVectorBoolSSE(int *health, uint8_t *pOutput, int limit) {
uint16_t mask[16] = { 0 };
const size_t lenDiv16y16 = (arrayLength / 16) * 16; // full packs of 16 values...
const __m128i sse127 = _mm_set1_epi8(127);
const int8_t ConvertedThreshold = ThresholdValue - 128;
const __m128i sseThresholds = _mm_set1_epi8(ConvertedThreshold);
auto pInputData = signedInputValues.get();
auto pOutputByte = alignedOutputValues;
for (size_t j = 0; j < lenDiv16y16; j += 16)
{
const auto in16Values = _mm_set_epi8(pInputData[15], pInputData[14], pInputData[13], pInputData[12],
pInputData[11], pInputData[10], pInputData[9], pInputData[8],
pInputData[7], pInputData[6], pInputData[5], pInputData[4],
pInputData[3], pInputData[2], pInputData[1], pInputData[0]);
const auto cmpRes = _mm_cmpgt_epi8(in16Values, sseThresholds);
const auto packed = _mm_movemask_epi8(cmpRes);
*((uint16_t *)pOutputByte) = static_cast<uint16_t>(packed);
//*pOutputByte++ = (packed & 0x0000FF00) >> 8;
//*pOutputByte++ = packed & 0x000000FF;
pOutputByte += 2;
pInputData += 16;
}
}
Digging through Intel's documentation and the forums, I found that this isn't a full-fledged intrinsic but a helper that generates extra instructions:
_mm_set_epi8 is not a direct hardware instruction but a helper intrinsic that generates multiple instructions to construct the desired SIMD register. This adds complexity compared to direct memory loads or other simpler instructions. (stolen from intel forum)
so it's better to use a different intrinsic, lucky for us that our algorithm and use case allow it.
alignas(16) int8_t data[16] = {15, 14, 13, ..., 0};
__m128i reg = _mm_load_si128((__m128i*)data);This gave the final variant, which delivered the needed speedup. The algorithm processes an array of integers (pValues), checking for each value whether it exceeds the threshold (the threshold is set by the limit variable), and builds an output array (pOutput) that stores bit masks for each set of values. Vectorizing the array processing lets you handle 16 values in a single instruction (on consoles you can extend it to 32 per operation, AVX2), significantly speeding up execution compared to traditional loops. Reducing the number of memory operations and getting rid of branches further increases the algorithm's speed.
const size_t lenDiv16y16 = (testLen / 16) * 16; // full packs of 16 values...
const __m128i sse127 = _mm_set1_epi8(127);
const int8_t ConvertedThreshold = limit - 128;
const __m128i sseThresholds = _mm_set1_epi8(ConvertedThreshold);
auto pInputData = pValues;
auto pOutputByte = pOutput;
for (size_t j = 0; j < lenDiv16y16; j += 16) {
const auto in16Values = _mm_loadu_si128(reinterpret_cast(pInputData));
const auto cmpRes = _mm_cmpgt_epi8(in16Values, sseThresholds);
const auto packed = _mm_movemask_epi8(cmpRes);
*((uint16_t *)pOutputByte) = static_cast(packed);
pOutputByte += 2;
pInputData += 16;
}
All of this together brought the time to build the bitmaps on large and ultra-large maps (256 and 1024 tiles per side respectively) down from 4 ms to 1 ms per frame. It depends, of course, on the hardware too: on consoles the results came out more stable.
Conclusions
- Branches are expensive, even on modern CPUs, but you should only fight them in very special tasks.
- Benchmarks are a very sketchy business: the effect with thresholds at 32, 64, 128 was practically not observed on the latest-generation Ryzens. Yep, those are the results — all our gadgets turned out useless, but there are plenty of other problems there.
- The pattern is quite narrowly specialized: increasing the map size reduced the effect — it showed up most clearly on 256×256-tile maps, while larger maps gave similar results.
- Attention to branches matters, especially in hot functions, since it can substantially boost performance — just check that spot 33 times with a profiler first.
- Don't rush to swap your own reinvented wheel for the standard bitset; it doesn't always work out for the better.