
This is the fifth chapter of the PragmatiC++ draft — a book on pragmatic C++ that still makes sense a year later. The chapter source is open on GitHub.

In the previous articles I covered how overloads work and how the compiler finds the right functions in associated namespaces, but what happens when the compiler finds not one but several matching overloads at once? This question becomes especially relevant when working with templates and concepts, because one and the same type can satisfy the requirements of several functions simultaneously, and this is where the mechanism for selecting the most suitable overload comes into play. Without this selection the entire requires-and-concepts system wouldn't work.
How does the compiler pick the best overload when there are several suitable variants? Intuitively we expect that a more "precise" function should take priority over a more general one, and we often carry this expectation into the rules we give the compiler when writing templates and constraints. The general idea here is the following: overloads can be not just enumerated but arranged into a hierarchy by degree of specificity; then some functions describe a wide class of types, others a subset of it, and once the argument type is known, the compiler should pick the function whose requirements most precisely match that type. This logic is built right into the C++ standard and is called partial ordering, precisely because not all overloads are necessarily comparable with each other.
At the heart of partial ordering lies the notion of subsumption — or, speaking informally, one set of requirements subsumes another if every type satisfying the stricter requirements automatically satisfies the weaker ones too. In that case the stricter variant is considered more specialized and wins during overload selection.
Let's return to the resolve() example from the previous article, where we had two versions of the function:
template<typename T>
void resolve(T x) requires std::integral<T>;
template<typename T>
void resolve(T x) requires std::integral<T> && (sizeof(T) > 4);The first function takes any integral type, while the second takes only those integral types whose size is greater than four bytes. Obviously the set of types of the second function is a subset of the set of the first, and any type that fits the second version automatically fits the first, but not vice versa.
And if we call resolve(10ull), then both overloads formally fit: long long is an integral type, and on most platforms its size is greater than four bytes, and the compiler doesn't end up at a dead end, because it compares the constraints and sees that the second version is stricter, i.e. more specialized, and it's exactly the one chosen — without any ambiguity and without the need for additional hints from the programmer.
This is a very important difference from the old SFINAE-based techniques, when such behavior had to be ensured manually: adding dummy parameters, complicating enable_if conditions, watching the order of overloads and hoping the compiler interprets them the way it was intended.
With concepts, however, this hierarchy becomes part of the formal model of the language rather than a side effect of tricks, but it's still worth remembering that partial ordering isn't a panacea for all errors either, and there are situations where two sets of requirements don't subsume one another. For example, one concept may constrain a type by size, and another by the presence of a certain operation, and neither is stricter in the general case. In such situations the compiler will honestly report an ambiguity, because from the standpoint of formal logic it really has no grounds to prefer one variant over the other.
#include <concepts>
#include <iostream>
// Concept: the type has a size greater than 4 bytes
template<typename T>
concept LargeType = sizeof(T) > 4;
// Concept: the type supports the increment operation
template<typename T>
concept Incrementable = requires(T t) {
{ ++t } -> std::same_as<T&>;
};
// First overload: requires a large size
template<LargeType T>
void process(T value) {
std::cout << "Large type version\n";
}
// Second overload: requires increment
template<Incrementable T>
void process(T value) {
std::cout << "Incrementable version\n";
}
int main() {
long long x = 42; // Satisfies both concepts!
process(x); // Compile error: ambiguity!
// long long is both LargeType and Incrementable,
// but neither concept is stricter than the other
return 0;
}
<source>:31:5: error: call to 'process' is ambiguous
31 | process(x); // Compile error: ambiguity!
| ^~~~~~~
<source>:18:6: note: candidate function [with T = long long]
18 | void process(T value) {
| ^
<source>:24:6: note: candidate function [with T = long long]
24 | void process(T value) {
| ^The concept hierarchy and the partial-ordering mechanism together let you build overloads as a system of refining contracts, where you can start with the general case and gradually add more and more specialized versions without fear of conflicts and unexpected behavior. The compiler takes these refinements, builds a table of strict comparisons on their basis, and predictably picks the most suitable function, guided by exactly the requirements we explicitly formulated in the code.
What "stricter" means
Now let's figure out what exactly the word "stricter" means in the context of requires and concepts. Here it should be noted right away that we're talking not about the programmer's subjective feeling (an imprecise agreement as it was in SFINAE) but about a formal relation between conditions that the compiler is able to analyze (constraints).
The intuitive explanation is fairly simple: if from the fulfillment of condition A the fulfillment of condition B automatically follows, then A is considered more specialized and B more general. Or like this: the set of types satisfying A is a subset of the set of types satisfying B. Now, if the compiler has to choose between overloads, it prefers the one whose requirements are stricter, because it describes a narrower and more precise case.
For example, the condition std::integral<T> && sizeof(T) > 4 is stricter than just std::integral<T>, because any type satisfying the first condition necessarily satisfies the second too, but not vice versa. Similarly, requires (sizeof(T) == 4) is stricter than requires (sizeof(T) >= 1): being equal to four bytes automatically means the size is not less than one byte, but that's only a special case of the more general condition.
// General condition: any integral type
template<typename T>
requires std::integral<T>
void process(T value) {
std::cout << "General integral version\n";
}
// Stricter condition: integral type larger than 4 bytes
template<typename T>
requires std::integral<T> && (sizeof(T) > 4)
void process(T value) {
std::cout << "Large integral version (size > 4)\n";
}
// Another example with different levels of specificity
template<typename T>
requires (sizeof(T) >= 1) // Very general condition
void display(T value) {
std::cout << "Any type with size >= 1\n";
}
template<typename T>
requires (sizeof(T) == 4) // Stricter condition
void display(T value) {
std::cout << "Exactly 4 bytes\n";
}
int main() {
int x = 42; // 4 bytes on most platforms
long long y = 100; // 8 bytes on most platforms
short z = 5; // 2 bytes
process(x); // Calls the first version (int is usually 4 bytes, not > 4)
process(y); // Calls the second version (long long > 4 bytes)
process(z); // Calls the first version (short < 4 bytes)
std::cout << "\n";
display(y); // Calls the first version (sizeof(long long) >= 1, but != 4)
display(z); // Calls the first version (sizeof(short) >= 1, but != 4)
return 0;
}
Program stdout
>> General integral version
>> Large integral version (size > 4)
>> General integral version
>> Any type with size >= 1
>> Any type with size >= 1The compiler isn't a programmer and doesn't reason "intuitively," as shown above, so in the C++ standard these relations are strictly formalized through the notion of subsumption — the subordination of one set of constraints to another. One set of constraints subsumes another if every disjunctive element of the first includes all the conjunctive elements of the second. The wording sounds heavy, but behind it lies quite concrete logic.
To be able to compare constraints, the compiler first brings them to a structured form and breaks the requires expression into elementary components, treating the logical connectives && and || not as arbitrary expressions but as logical operations over sets of requirements. After that a pairwise comparison of these elementary conditions takes place.
Consider a simple example with logical OR:
requires (std::integral<T> || std::floating_point<T>)This means that the type must be either integral or floating-point: that is, two alternative paths of satisfying the conditions are allowed, and only if neither of them is satisfied is the constraint unmet. This is a disjunction — a set of alternative requirements. And now let's look at an example with logical AND:
requires (std::copyable<T> && std::movable<T>)Here the situation is the reverse: both checks must be true simultaneously. The type is obliged to be both copyable and movable. This is a conjunction — a set of requirements, each of which is mandatory.
The compiler collects requires constraints into logical formulas built from atomic predicates connected by && and ||, doesn't prove (because the Great Programmer wrote it that way) their truth in the general logical sense, but compares their structure and checks whether one constraint follows from another at the level of syntactic form.
And here we arrive at a very important and often unexpected detail: two constraints are considered identical only if they syntactically coincide. Logical equivalence plays no role in this case, because the compiler doesn't deal with logical operations and doesn't simplify expressions to a canonical form — well, because that would require introducing into the compiler a mathematical apparatus for proofs of this kind.
template<typename T>
concept TrueConcept = true;
template<typename T>
concept AlsoTrueConcept = (C<T> && true);From the standpoint of logic and common sense the concepts TrueConcept and AlsoTrueConcept are equivalent, and this is usually taught to first-year students in logic lectures. Both are always true, but for the compiler these will be different expressions, because their syntactic structure differs, and the standard directly says that such constraints aren't considered equivalent.
The consequences of such "clever" constraints on the programmer's part can be quite unpleasant. If we overload functions with requires TrueConcept<T> and requires AlsoTrueConcept<T>, then the compiler ends up in a situation where neither overload subsumes the other, because they're logically equal but formally incomparable. As a result we simply get an overload ambiguity, and the standard allows the compiler to issue an error of the form "ambiguous overload, no diagnostics required," i.e. even without the guarantee of an understandable message.
"Two atomic constraints are considered identical if they are formed from the same expression at the source level and their parameter mappings are equivalent."
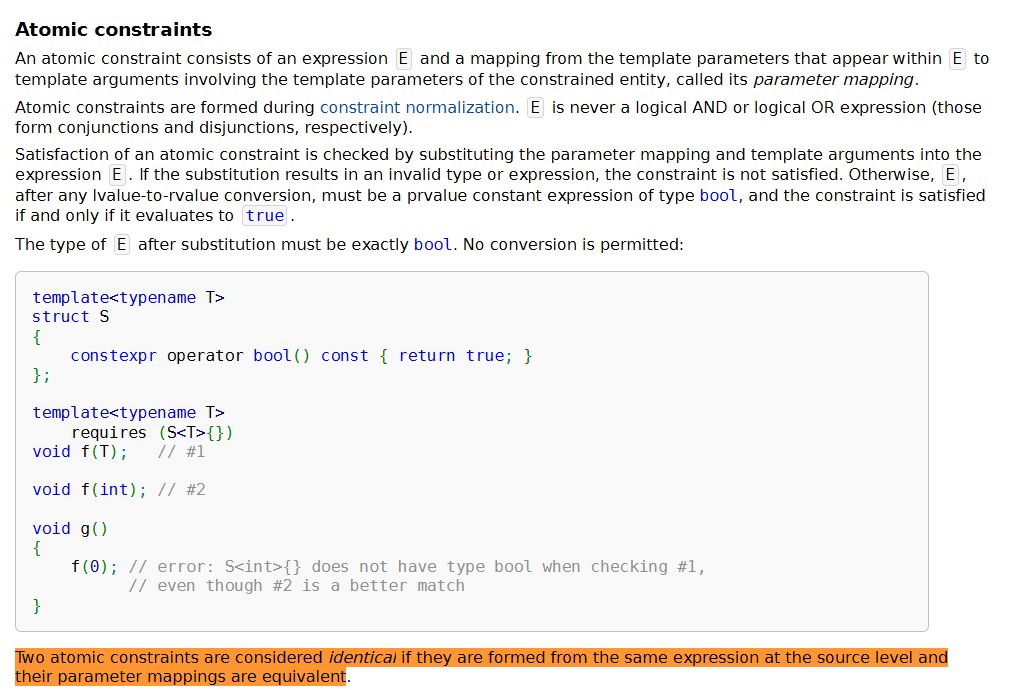
And this moment illustrates well the general philosophy of constraints and concepts, which make template code more strict and formal but in return require discipline from the programmer. If you want the compiler to see the hierarchy and specialization, express constraints explicitly, simply and uniformly, but don't rely on logical identities and "obvious" transformations — the compiler won't make them, because it has no mathematical apparatus for this.
How it works in practice
Now let's move from the formal model the standard gives us to the practical consequences a developer faces in real code. At this stage many developers start to feel a slight divergence between "how the system seems like it should work" and "how it actually works."
A situation often arises where, by meaning, one function clearly should "subsume" another, but the compiler "doesn't see" it, and the cause is almost always the same — the constraints are formulated slightly differently. To a human these formulations look equivalent (logically straight) or obviously connected (logically curved), but for the compiler they'll just be different syntactic constructs between which there's no formal relation of connection.
The typical symptoms are an unexpected overload ambiguity or the selection of a different version of the function than you expected. In such cases the problem is almost never in the requires mechanism itself, but in exactly how the constraints were expressed, so the general and proven technique is: don't duplicate composite constraints by hand, but move them out into a separate concept. For example, instead of writing in several places:
requires (Resolvable<T> && IsPath<T>)it's far more reliable to define a single concept:
template<typename T>
concept ResolvablePath = Resolvable<T> && IsPath<T>;and then use it directly:
requires ResolvablePath<T>Because as soon as you slightly change one of the five places where such a record was, the remaining four places will automatically differ. And it sometimes gets ridiculous.
// An attempt to create a general and a specialized version
template<typename T>
requires (Resolvable<T> && IsPath<T>)
void unified_process(T item) {
std::cout << "General version\n";
}
// Specialization with IsAbsolute
template<typename T>
requires (Resolvable<T> && IsPath<T> && IsAbsolute<T>)
void unified_process(T item) {
std::cout << "Specialized for absolute paths\n";
}
// Another programmer adds their version, but writes it in a different order
template<typename T>
requires (IsPath<T> && Resolvable<T> && IsAbsolute<T>) // Different order!
void unified_process(T item) {
std::cout << "Another specialized version\n";
}
// unified_process(fp); // ERROR: ambiguous
// The compiler sees TWO specializations with IsAbsolute,
// but they're syntactically different and it can't
// determine which one is "more specialized"From a human's standpoint a solution with a single entry point, i.e. one concept and constraints, changes nothing, but from the compiler's standpoint the situation becomes fundamentally better — now the constraints have a common name and a single syntactic form, which lets it correctly build the hierarchy, compare overloads and apply partial-ordering rules without surprises. In essence, you help the compiler see the very structure you were holding in your head anyway.
A good example of a consciously designed concept hierarchy is the standard library's iterator concepts. In the STL they're arranged not as a set of independent checks but as a strict ladder of abstractions, where input_iterator is at the bottom level, then come forward_iterator, bidirectional_iterator and finally random_access_iterator, and each next concept includes the previous one and adds new requirements.
┌─────────────────────────┐
│ input_iterator │
│ (base level) │
│ - read elements │
│ - move forward │
└───────────┬─────────────┘
│
│ includes + adds
│ multi-pass guarantees
▼
┌─────────────────────────┐
│ forward_iterator │
│ - all of input │
│ + multiple passes │
└───────────┬─────────────┘
│
│ includes + adds
│ backward movement
▼
┌─────────────────────────┐
│ bidirectional_iterator │
│ - all of forward │
│ + operator -- │
└───────────┬─────────────┘
│
│ includes + adds
│ random access
▼
┌─────────────────────────┐
│ random_access_iterator │
│ - all of bidirectional │
│ + operator [] │
│ + arithmetic │
│ + O(1) movement │
└─────────────────────────┘The idea here is simple and elegant: any random_access_iterator is a bidirectional_iterator, any bidirectional_iterator is a forward_iterator, and so on. This is expressed directly in the definitions of the concepts. For example, forward_iterator is formulated through input_iterator and additional requirements on the iterator category. As a result there's a clear subsumption relation between these concepts that the compiler is able to analyze automatically.
The practical consequence of this hierarchy is clearly visible in overload selection. Imagine two versions of the distance() function:
template<std::input_iterator It>
void distance(It it, It e);
template<std::random_access_iterator It>
void distance(It it, It e);If we call distance() with an iterator of std::vector<int>, the compiler will without hesitation choose the second version, because the vector's iterator satisfies both concepts, but std::random_access_iterator is stricter and therefore more specialized. This is exactly what the programmer expects: for a more powerful iterator a more efficient implementation is used.
But even with all the formal strictness of concepts, complex and deep hierarchies can lead to unexpected collisions, as Alexandrescu has repeatedly pointed out in his talks, where his position comes down to a simple but mature thought: not every hierarchy is worth encoding through overloads and partial ordering. In real code it sometimes turns out simpler and more reliable to express the selection logic explicitly than to hope for the automatic mechanism, and instead of a multitude of overloads you can write a single function and use if constexpr inside it:
if constexpr (std::contiguous_iterator<It>) {
// the fastest version
} else if constexpr (std::random_access_iterator<It>) {
// version for random access
}Such code is often easier to read, easier to debug and easier to extend. It explicitly shows the order of priorities and doesn't require the reader to understand the subtleties of subsumption among a dozen concepts. And both Herb Sutter and Alexandrescu noted that it's not always worth chasing maximal genericity at the cost of readability and predictability. Concepts are just a tool, not an opportunity to show off your cleverness; they're good for formalizing interfaces and expressing contracts, but they aren't obliged to solve all your architecture problems for you. Or, for example, overly strict constraints for every sneeze.
template<typename T>
concept Readable = requires(T t) {
{ *t };
};
template<typename T>
concept Incrementable = Readable<T> && requires(T t) {
{ ++t } -> std::same_as<T&>;
};
template<typename T>
concept Decrementable = Incrementable<T> && requires(T t) {
{ --t } -> std::same_as<T&>;
};
template<typename T>
concept Comparable = Decrementable<T> && requires(T a, T b) {
{ a < b } -> std::convertible_to<bool>;
};
template<typename T>
concept Arithmetic = Comparable<T> && requires(T a, typename std::iterator_traits<T>::difference_type n) {
{ a + n } -> std::same_as<T>;
{ a - n } -> std::same_as<T>;
};
template<typename T>
concept IndexAccessible = Arithmetic<T> && requires(T a, typename std::iterator_traits<T>::difference_type n) {
{ a[n] };
};
template<typename T>
concept FastDistanceMeasurable = IndexAccessible<T> && requires(T a, T b) {
{ a - b } -> std::convertible_to<typename std::iterator_traits<T>::difference_type>;
};
template<typename T>
concept Contiguous = FastDistanceMeasurable<T> && std::contiguous_iterator<T>;To sum up, the picture is as follows — the compiler picks an overload based on the strictness of the requires constraints and the formal relations between them, which lets you build concept hierarchies and write expressive, type-safe interfaces, but the syntactic identity of constraints matters more than their logical equivalence, and overly complex hierarchies can hurt code clarity.
As at the end of the previous article, where I talked about the need for moderation in constraints, here too I repeat the thought that good design combines carefully extracted concepts and a sound balance between compiler automation and explicit logic in the code — all of which helps create code that not only works correctly but also stays understandable to other developers. Nevertheless, for all its power, the concept system has limits of applicability, and it's important to understand where those limits lie — and that will be the subject of the next chapter...
← All books