

A long time ago, back when the riding cat had its "note number six" adventure, and my knowledge of allocators and experience using them was limited to the linear and the system ones, my team was reassigned to help another team that worked on navigation systems for large ships. Riding cats, especially the younger ones, are creatures who rarely study the documentation in detail; more often they skim the bit about the project's system interfaces, malloc, new, system allocators, and figure they now surely understand how it all works. And then the job goes: "Forget everything you knew. You didn't read all the way to page eight-hundred-something of the spec — there's a custom allocator here, and it's genuinely bad."
That's roughly how my dive into the world of abnormal memory allocation began. These days I know a dozen different allocators and the specifics of how they work — the specifics are admittedly more about games, but I think many people will be curious why all those "dances with allocators" are needed. In that article all the allocators are still more or less normal, but there are abnormal ones too — and it turns out they're needed as well, and in certain areas of development they're quite important and actually used.
But as for why the abnormal ones are needed and important, there are almost no explanations — nor implementations in the public domain. In this article I'll tell you which abnormal memory-allocation algorithms I've come across, what they live on, what they eat, and why malloc sometimes pretends it has nothing to do with it — and yes, malloc can return null, and we were wrong to remove that check.
To understand how an allocator is built, you can picture it as a small memory-management system inside the program. It's responsible for allocating, handing out, freeing, and — when necessary — fully destroying regions of memory. You can usually pick out five basic operations that describe how any allocator works (although not every allocator necessarily supports them all explicitly).
create / creating the allocator
Initializes the allocator: it's given a certain region of memory — this could be, for example, a pre-reserved fixed-size buffer or a block obtained from the system allocator (e.g. via malloc or VirtualAlloc). In essence the allocator starts to "live" inside this region and manage it on its own, handing out memory at the program's request. The key idea is that after a create call the allocator no longer talks to the operating system directly. It works inside the space allotted to it, which makes allocations faster and more predictable.
allocate / allocating a block
Used to request memory from the managed region: the program says how many bytes it needs, and the allocator looks for a suitable spot inside its space and returns a pointer. Depending on the allocator type this may be just a linear offset or a more complex search for a suitable block. The key feature is speed (the parameter every developer fights for); allocate often runs in O(1) because the allocator knows how its memory is laid out and doesn't need the complex algorithms of system memory managers.
deallocate / freeing a block
Does the opposite — frees a specific block previously allocated via allocate (which isn't free either). In simple (linear) allocators this operation may not be provided at all, and then memory is cleared all at once when some event occurs. Freeing a block doesn't always mean physically erasing the data — sometimes it just updates internal tables or flags.
free / resetting all allocations
Clears all allocated blocks, but doesn't destroy the allocator itself or return memory to the system. It's essentially a "mass reset", after which it can serve new requests again, starting from the beginning of its buffer.
destroy / destroying the allocator
Ends the allocator's life, frees the memory region it was given at creation, and removes its internal structures. After a destroy call the allocator can no longer be used, and all pointers it handed out become invalid.
Everything above holds for all types and kinds of allocators, but the specific goals of the "abnormal" allocators are often very far from the understanding of a developer who meets them for the first time.
The good…
"Optimizing" would be the more fitting word here, but then there'd be no pretty title. While developing the workstation for the watch navigator — who organizes the navigation service and oversees the navigators' work — one large customer demanded the use of their own version of GCC (clang was still in diapers back then) with the ability to dump memory statistics: literally how many and which objects were created, where they were located, when they were destroyed, and so on. While porting the software onto this fork (and there were not only these requirements but a bunch of other quirks and extensions, like being unable to allocate more than 1 MB of memory at a time), a custom allocator with object-lifetime tracking appeared.
It distributed objects across memory pages based on their predicted lifetime, which was gathered from previous runs in the form of a config. For example, objects that exist for just a few frames went into one pool, and long-lived ones into another. Per the spec this was "in theory" supposed to reduce fragmentation and make it possible to free objects with similar lifespans in batches (by page): when some event occurred, the pages with short-lived objects were meant to be cleared wholesale (didn't take off in reality).
On the plus side, integration with the statistics tools after runs made it possible to automatically (via the config) "train" the allocator to predict lifetimes based on real execution data, reducing the need for manual tuning.
In reality this approach showed decent results when used in the navigator workstation's database: it did start eating less memory, though not in terms of speeding things up. But it spawned a separate fork of the allocator that helped with leak profiling, since each memory page is tied to a specific lifetime category. In the end the system was mediocre as an allocator, but it kick-started specialized software that let us track memory leaks at runtime without a significant performance hit. Later, part of this system's work was ported (by a different team) into the общий clang repo and made the sanitizer itself a bit faster.
Roughly speaking, using ASan leads to a 2–3x slowdown, whereas the "good" one slowed the program down by no more than 10%. Each memory page got metadata bound to a lifetime category and provided detailed leak tracing, letting you identify problem areas of the code down to specific functions and modules. But the need for up-front manual tuning, the complexity of integration, and the reworking of a large part of the application code kept this development within the walls of a single company.
As part of this same work, another type of allocator was being developed, aimed at simulating long-term use of programs — because navigation complexes run continuously for weeks and months with no chance to restart.
LIFETIME-TRACKING ALLOCATOR
═══════════════════════════════════════════════════════════════════
┌─────────────────────┐
│ NEW OBJECT │
│ memory request │
└──────────┬──────────┘
▼
┌─────────────────────┐
│ ANALYSIS/PREDICTION│
│ of lifetime │
|heuristics + stats │
└──────────┬──────────┘
┌──────────────┼──────────────┐
▼ ▼ ▼
╔═══════════════╗ ╔═══════════════╗ ╔═══════════════╗
║ PAGE A ║ ║ PAGE B ║ ║ PAGE C ║
║ Short-lived ║ ║ Medium-lived ║ ║ Long-lived ║
║ (1-3 frames) ║ ║(minutes/hours)║ ║(days/weeks) ║
╠═══════════════╣ ╠═══════════════╣ ╠═══════════════╣
║ [obj][obj][ ] ║ ║ [obj][ ][obj] ║ ║ [obj][obj] ║
║ [obj][ ][ ] ║ ║ [ ][obj][ ] ║ ║ [obj] ║
║ [ ][ ][obj] ║ ║ [obj][obj] ║ ║ [ ][obj] ║
╠───────────────╣ ╠───────────────╣ ╠───────────────╣
║ META: TTL=3 ║ ║ META: TTL=600 ║ ║ META: TTL=∞ ║
║ Category: 1 ║ ║ Category: 2 ║ ║ Category: 3 ║
║ Trace: func_A ║ ║ Trace: func_B ║ ║ Trace: func_C ║
╚═══════════════╝ ╚═══════════════╝ ╚═══════════════╝
▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│ CLEANUP │ │ CLEANUP │ │ CLEANUP │
│ whole │ │ partial │ │ rarely │
│ each │ │ as it │ │ on │
│ frame │ │ expires │ │ request │
└─────────┘ └─────────┘ └─────────┘
LEAK TRACKING:
════════════════════
Time N: [A: ████░░] [B: ███░░░] [C: ████░░] ← state
Time N+10: [A: ████░░] [B: ████░░] [C: ████░░] ← normal
Time N+50: [A: ████░░] [B: █████░] [C: █████░] ← growing
Time N+99: [A: ████░░] [B: ██████] [C: ██████] LEAK
▲ ▲
┌───────┴───────────┴────────┐
│ DETAILED TRACE OF B: │
│ • Function: path_trace() │
│ • Module: ppath.cpp:342 │
│ • Expected: 600 sec │
│ • Actual: ∞ │
└────────────────────────────┘The bad…
While testing complex, long-running systems like the software from the previous part, the need arises to "prove" the system's stability over long usage periods — which is in fact practically unachievable during development (what long-term testing can there be when updates land every day). Add to that the difficulty of catching memory-management errors that show up extremely rarely — sometimes only after days or weeks of continuous real operation. The company had several fully functional test benches as close as possible to a ship's conditions and data, where the software, as the saying goes, "lived" on real recordings from ships — but there were only three, and the queue to push your own module's testing through them was booked a month ahead.
To somehow speed up finding this kind of error, a separate type of allocator was developed — a randomizing (chaos) one, a specialized memory-management system built to hunt for bugs related to long-term program use.
Unlike "good" allocators, where the developer strives for stable object placement to optimize the cache and make data fetches predictable, this allocator does exactly the opposite — it deliberately breaks the stability of the address space. On every new allocation the system may randomly move already-existing objects to arbitrary regions of memory, creating conditions close to unpredictable. Well, not on every one, of course — that's the harshest case; rather, on some event plus a timer. Which, naturally, helps catch (relatively quickly, compared to ordinary development) the pieces of code that rely on addresses staying put — one of the classic sources of hard-to-catch bugs.
So that such moves don't break the program, the allocator uses an internal address-translation table — a kind of descriptors. It maps the "logical" addresses the application works with to the real physical addresses in memory. Thanks to this, objects can move freely while correctly written code keeps working without noticing the changes. The program, as usual, "thinks" the data is in its old place, though in reality it has already been moved to another part of memory.
Using this approach made it possible to catch a number of bugs at early stages that would normally have surfaced only after long operation. In one case an application that relied on address stability started crashing within a few hours of enabling aggressive address randomization, whereas without it similar failures happened only after weeks — and most likely already on the customer's equipment, i.e. somewhere at sea, where pulling out dumps is practically impossible, which threatened a serious dressing-down from management and some financial trouble. To avoid all kinds of problems, a ship always runs 2 or more backup instances of each workstation in parallel, so that if something happens you just switch to a live one if one falls over; that did happen, but very, very rarely.

In another case, in a navigation module working with multithreaded database queries, we managed to find data races. One thread cached the address of a structure while another triggered its relocation, leading to data corruption and a ship-positioning error. After analysis and a long investigation we concluded that such a situation couldn't have happened on real hardware and was most likely an effect of the allocator's approach itself — but the precedent was there, and that code was fixed. Again: in real conditions this error could occur about once per couple of billion DB accesses (which on average was three times more than the number of accesses in a single voyage), but the cost of such an error would be the ship's plotted position shifting by several dozen meters from its real one.
Such an allocator can be seen as a stress-tester for memory subsystems: it models unpredictable environment behavior and helps surface bugs that depend on the timing and ordering of operations, letting you check in advance how robust the architecture is to fragmentation, random failures, and incorrect accesses. It has to be said that after running tests on this allocator a great deal of our software at the time "fell apart", which led to handing out a large number of tickets to various departments and, on the whole, to rethinking our approach to working with memory.
The colored…
Let me say a little about a very specialized allocator that you most likely won't meet in everyday life and will never use. Usually it's either an in-house research project of a studio aimed at finding bugs, debug builds, and internal tools. They're also sometimes shown at GDC in the "look at the thing we hacked together" section. Such things aren't aimed at performance anymore; they solve their own narrow, specialized tasks.
The "colored" allocator introduces the concept of "memory colors" to strictly separate the data of different subsystems. Each allocation is accompanied by a color tag (RED, BLUE, GREEN, etc.), and the allocator maintains an internal table mapping memory pages to colors. Operations between different colors are forbidden at the debug-mode level, and the allocator provides its own memset, memcpy, and other functions: an attempt to copy, move, or work with memory of another color from a "colored component" raises a warning, a log entry, or an error message — which helps find cases of data being mistakenly mixed between systems.
In production mode the check is disabled for better performance, but in debug mode the allocator can track the color of every memory page, preventing accesses to memory of the "wrong" color. On top of that, people sometimes add a "color barriers" mechanism, where one color can read another but not modify it (useful for implementing immutable patterns or protecting thread data).
ColorAllocator alloc;
auto red_data = alloc.allocate<RED>(256);
auto blue_data = alloc.allocate<BLUE>(256);
// Safe: working within a single color
alloc::memset(red_data, 0, 256);
// Error: trying to copy memory between colors
alloc::memcpy(blue_data, red_data, 256); // assert: page color mismatch!I happened to work as a consultant with the Arkane team on the AI logic of the characters in Deathloop, and one of the development problems was the complexity of interaction between tasks and threads: some tasks went into a common queue, others temporarily became threads. The game-world logic, the renderer, and the physics constantly accessed shared data, which led to bugs that were extremely hard to debug and to data races that very negatively affected the behavior of the game's dummies — and they weren't exactly "shining with intellect" to begin with, and here they'd also periodically and outright go dumb when interacting with the player and the world.
Not for the needs of AI but for debugging in general, the engine team decided to introduce an experimental color-based memory-allocation mechanism: each thread was assigned its own color. Roughly, the red thread was responsible for game logic, blue for rendering, green for physics, and a task's shade came from the color of the thread that created it. An attempt to write data of one color from another thread raised an error and surfaced an absolutely enormous number of synchronization problems. This colored allocator was built on top of TLSF.
We caught a heap of different problems, hidden memory corruption, and all sorts of inconsistencies. Beyond threads, a bit later this mechanism was applied to isolating subsystems — and there we found data "leaks" between the renderer and the rest of the game code. In testing we discovered that the animation subsystem was "accidentally" modifying physics data, which caused strange "jerks and teleports" of characters; fixed.
Another use case was made for immutable data. We only thought it was immutable; the game simply didn't care. Resources marked as "read-only" (PURPLE) weren't allowed to change after the level started — there too we found quite a few bugs, which greatly simplified life for the QA department before release.
┌───────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ RED │ │ BLUE │ │ GREEN │
│ (Game Logic) │ │ (Rendering) │ │ (Physics) │
│---------------│ │------------------│ │------------------│
│ Object A │ │ Vertex Buffer │ │ Collision Map │
│ Object B │ │ Texture Data │ │ Rigid Bodies │
└───────┬───────┘ └────────┬─────────┘ └────────┬─────────┘
│ copy │ copy │
│ forbidden V allowed │
^----------------------V ^-----------------V…and the fast one (TLSF)
In software development there's no single standard or memory-allocation algorithm that's equally effective for all use cases. Game engines differ greatly from ordinary applications in their memory-usage patterns: they need predictable performance (here they're closer to an RTOS), minimal allocation latency (here we borrow a bit from embedded systems), and strict control of memory fragmentation (that's already a purely gamedev wish).
The algorithm that best fits these three parameters is the two-level segregated-fit list (an implementation can be found here), which guarantees constant-time allocation and deallocation operations and a low level of fragmentation.
The allocator uses a "good fit" strategy, allocating the minimum amount of memory sufficient to hold the requested data. This best matches the memory-usage pattern of game engines — allocations happen in relatively narrow size ranges: game objects, system components, temporary buffers. This method also minimizes fragmentation compared with alternative strategies such as "first fit", since fragmentation can make it impossible to allocate memory for large resources (models, AI, or sound files) even when there's enough total free memory. "Best fit" minimizes fragmentation better but loses on speed, so that strategy is chosen less often (illustration by @Serpentine).
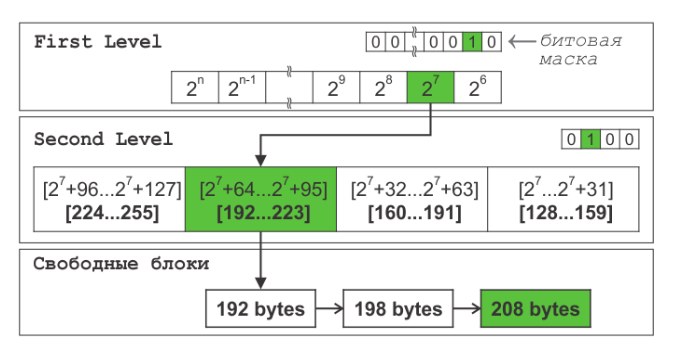
TLSF doesn't zero the allocated memory or check access rights to it, the way some allocators do, which improves overall performance. This is justified, since game engines run in a controlled environment where programmers aren't treated as a potential security threat. Initializing memory takes extra compute that's better spent on game logic, rendering, and processing game systems, and the responsibility for correctly initializing data lies with the developer. On the other hand it's very fast — the table below shows the number of CPU cycles (*) required for a single allocation in different implementations.
Size | malloc (std, win) | malloc (std, win) | DL’s malloc* | Binary Buddy* | TLSF* |
|---|---|---|---|---|---|
128 | 25636 | 112566 | 7376 | 4140 | 155 |
243 | 22124 | 91216 | 5660 | 4448 | 168 |
512 | 15974 | 82162 | 5445 | 4248 | 159 |
4097 | 14743 | 65661 | 3346 | 4135 | 162 |
…conclusion
You know what I've noticed over my time working on games? A ton of the memory we allocate lives for just a single frame. Seriously, a single frame! It's born, lives out its 16–33 milliseconds, and dies. But even so, there's no universal answer to the question "which allocator is better" — it all depends solely on the specific task.
It may sound old-fashioned, but I often take paper and a pencil (yes, yes, it's the twenty-first century out there, hence the pencil) and draw where the memory comes from and where it goes afterwards. Or I meditate over a memory-usage profiler — many laugh, until they see the result. It sounds strange, but such meditation really does help you understand how the system creates and uses data, so it's never too early to start thinking about memory. Whenever you start thinking about it, you'll still wish you'd done it even earlier — verified by my own bitter experience!
Примерно полгода назад я опубликовал на Хабре цикл статей про игровую разработку (начинать можно отсюда), который был хорошо принят сообществом. Мои знакомые и некоторые Хабровчане просили выложить эту информацию в более удобном и концентрированном виде — в виде курса по C++ или одной большой статьи. Решил сделать пробный шар в виде небольшого курса по программированию на C++ без аллокаций; он действительно небольшой — всего 45 уроков — и захватил пару статей из цикла, но если вам понравится, можно попробовать сделать ещё один по интересным темам (Нескучное программирование. С++ без аллокаций памяти). Курс платный, дабы отсеять охотников за халявными сертификатами и любителей пошуметь в комментах. Тем, кто меня читает, — промокод (HABR50); если нужна скидка больше или бесплатный инвайт, напишите в личку.
About six months ago I published a series of articles on Habr about game development (you can start here), which was well received by the community. Friends and some Habr readers asked me to lay this information out in a more convenient and concentrated form — as a C++ course or one big article. I decided to float a trial balloon in the form of a small course on programming in C++ without allocations; it really is small — only 45 lessons — and it picked up a couple of articles from the series, but if you like it, I might try to make another on interesting topics (Programming without the boredom. C++ without memory allocations). The course is paid, to filter out hunters for free certificates and people who like to make noise in the comments. For those who read me — promo code (HABR50); if you need a bigger discount or a free invite, drop me a DM.